Agentic Infrastructure Hits Sovereign Scale
From broken benchmarks to agent-owned wallets, the stack for autonomous operations is finally here.
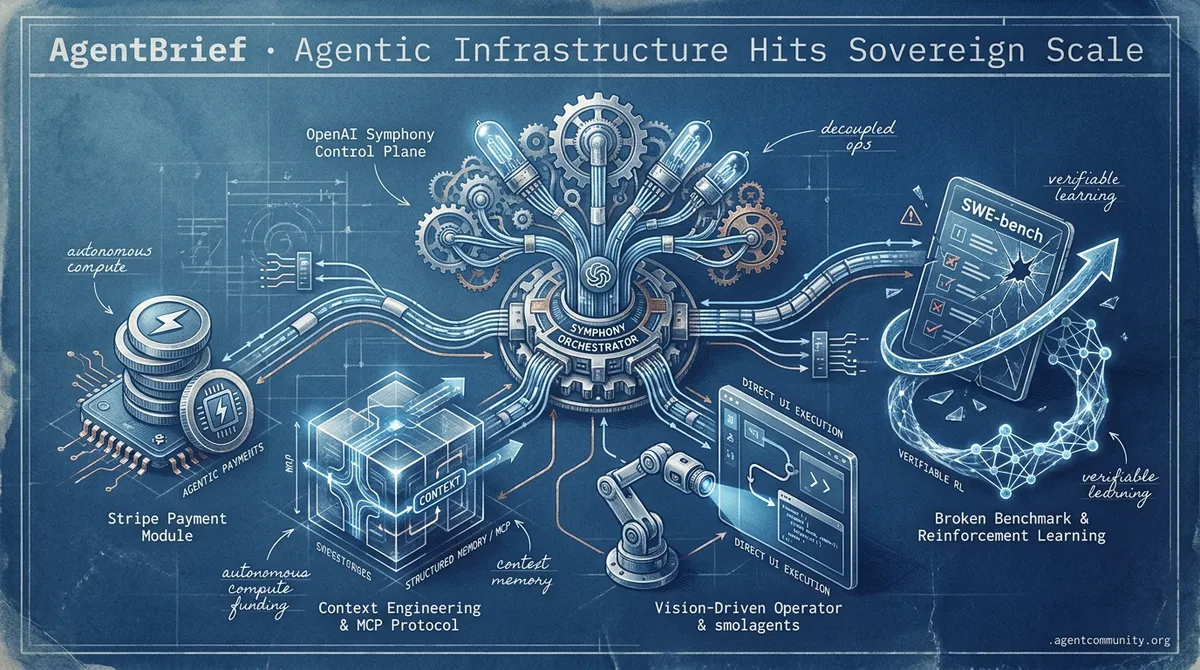
- Sovereign Agent Operations OpenAI's Symphony and Stripe's agentic payments are decoupling development from human bottlenecks, allowing agents to maintain repos and pay for compute autonomously.
- The Infrastructure Pivot The industry focus has shifted from raw model intelligence to 'context engineering' and protocols like Anthropic's MCP, prioritizing structured memory and efficient orchestration to solve the $4,000 API bill crisis.
- Execution over Interaction Vision-driven systems like OpenAI’s Operator and code-action frameworks like Hugging Face’s smolagents are replacing brittle JSON scraping with direct UI navigation and Python execution.
- The Benchmark Crisis With major benchmarks like SWE-bench exposed as potentially broken by UC Berkeley researchers, practitioners are moving toward verifiable reinforcement learning and deep research capabilities over leaderboard chasing.
The X Intel
The agentic web just gained its financial and operational backbone.
We are witnessing the infrastructure of the agentic web solidify before our eyes. This week wasn't about better chat interfaces; it was about the plumbing. OpenAI released Symphony, shifting agents from 'assistants' to 'autonomous repo maintainers' that live inside your ticketing system. Stripe finally gave agents a way to pay for their own compute and services without handing over the master keys. And Prime Intellect is letting us train these entities at scale using reinforcement learning. The common thread? We're moving away from the 'human-in-the-loop' bottleneck. When agents have their own wallets, their own orchestration specs, and their own self-improvement loops, the speed of development decouples from human typing speed. For those of us shipping today, the message is clear: stop building features and start building systems where agents can operate as sovereign entities. The 'agentic web' isn't a future state—it's the stack we are deploying right now.
OpenAI Open-Sources Symphony: Turning Linear Into an Agentic Control Plane
OpenAI has open-sourced Symphony, an agent orchestrator spec that turns issue trackers like Linear into always-on control planes for Codex-powered coding agents, assigning a dedicated agent to every open issue in an isolated workspace with its own Git branch and CI tests @OpenAIDevs. The system polls tickets, automatically queues and processes tasks in parallel, generates pull requests after passing CI, and enables auto-restart for stalled agents, shifting developers to high-level review @ainativedev @DataChaz.
Internal OpenAI teams reported a 500% increase in landed PRs within three weeks, with the reference implementation in Elixir and community ports to TypeScript/Python already underway @ryancarson. This release aligns with Sam Altman's rollout of GPT-5.5-Cyber, a frontier cybersecurity model being deployed to trusted cyber defenders for securing infrastructure, amid comparisons to Anthropic's Claude Mythos @sama.
AISI evaluations show GPT-5.5-Cyber achieving a 71% success rate on expert-level cyber tasks like memory corruption exploits and crypto breaks, solving a 32-step network takeover in 2/10 attempts (human expert: ~20 hours) and a reverse-engineering challenge in 11 minutes for $1.73 @rohanpaul_ai @NateBurnikell. Together, these advancements enable autonomous agent fleets operating across developer and security stacks @swyx.
Stripe’s Agent Rails: Secure Wallets and Per-Token Streaming Payments
Stripe is building dedicated infrastructure for AI agents, treating them as first-class entities with Link agent wallets that use the OAuth 2.0 device authorization grant (RFC 8628) for secure, scoped access without exposing payment credentials—users approve every purchase via CLI-generated device codes and shared passphrases, akin to smart TV logins @aakashgupta @stripe. This positions Stripe in the protocol race alongside Visa's TAP and others, enabling agents to become autonomous economic actors with forecasted millions of transactions by 2026 holidays @aakashgupta @stripe.
On the provisioning front, Stripe Projects—now available to everyone—allows developers and agents to programmatically spin up services like Supabase databases directly from the Stripe CLI, demonstrated in live sessions with no dashboard intervention required @kiwicopple @stripe. For micropayments, Stripe partnered with Tempo on the Machine Payments Protocol (MPP) and Metronome for streaming payments per token, tracking and settling usage in real-time as tokens are consumed—crucial for agentic workflows paying for inference on-the-fly @altryne @stripe.
Community reactions highlight governance challenges like liability and over-spend controls, but praise the shift to agent-native rails @stripe. This infrastructure is the missing link for agents that need to manage their own cloud resources and settle their own debts without human friction.
Prime Intellect’s Lab: A Full-Stack Factory for Self-Improving Agents
Prime Intellect has launched 'Lab' out of beta, a full-stack platform for building, evaluating, and training agentic models via RL on environments that include tasks, harnesses, and performance rubrics @PrimeIntellect @PrimeIntellect. Beta users ran over 10,000 training jobs on domains like browser use, data workflows, long-horizon coding, and GPU programming, using models from 1B to 400B parameters at pay-as-you-go pricing @PrimeIntellect @PrimeIntellect.
Related research shows RL-tuned harnesses boosting Terminal-Bench 2 pass@1 from 69.7% to 77.0%, outperforming human and Codex baselines with 12% fewer tokens on SWE-bench @agentcommunity_ @omarsar0. Zapier has already used Lab for RL on AutomationBench to detect reward hacks, signaling that major integrators are moving beyond simple prompting into fine-tuned agentic behaviors @PrimeIntellect.
Cohort II applications are now open for autonomous research and long-horizon evals, as the industry shifts toward verifiable domains where agents can be iteratively improved through environment-specific rewards @PrimeIntellect. For builders, this commoditizes the RL pipeline that was previously only accessible to labs with dedicated infrastructure teams.
In Brief
Sakana AI’s KAME Architecture Enables Voice Agents to 'Speak While Thinking'
Sakana AI introduced KAME, a tandem speech-to-speech architecture that resolves the speed-reasoning tradeoff by running a fast frontend model alongside an asynchronous backend LLM injecting 'oracle signals' mid-generation. This system allows a lightweight model like Moshi to handle the response loop while a swappable backend—like Claude Opus or GPT-4.1—provides progressive refinements without halting speech, mimicking human interaction @SakanaAILabs @hardmaru. While some developers report only marginal gains over optimized prompts on newer models, community reactions emphasize its potential to make voice AI 'feel remarkably more alive' through near-zero added latency @Marktechpost @PhantomByteAI.
LlamaParse MCP Server Launches Amidst Growing Protocol Skepticism
LlamaIndex has launched a production-ready MCP server for LlamaParse, allowing agents to parse documents into clean markdown via @WorkOS OAuth integration, but the release coincides with a debate over whether the Model Context Protocol (MCP) is over-engineered. While the server addresses MCP's lack of native file upload through custom token-based endpoints, practitioners like @signulll argue that excessive tool count can bloat context windows and advocate for letting models 'cook' with fewer abstractions @jerryjliu0 @llama_index. Defenders note that MCP standardizes integrations for precise enterprise operations, though scaling multiple servers remains a significant challenge for agent harnesses @dishant_ic.
White House Restricts Claude Mythos Expansion Over National Security Risks
The White House has opposed Anthropic's plan to expand access to its Claude Mythos model, citing concerns that the model's ability to autonomously discover and exploit software vulnerabilities poses a national security risk. Officials worry that broader access could accelerate the weaponization of flaws in critical systems, highlighting the dual-use nature of agentic AI where Mythos Preview achieved a 68.6% success rate on cyber-attack simulations @rohanpaul_ai. Agent builders now face an 'authorization gap,' as high-capability models increasingly require government permission layers beyond standard safety weights or data filters @asymmetricmind @emollick.
Quick Hits
Agent Frameworks & Orchestration
- The Codex CLI can now review actions, enabling more autonomous management of complex developer projects @tom_doerr.
- Blink-h released an 'Agent Startup Kit' for building reusable AI coding workflows for SaaS platforms @DanKornas.
- Deep Agents now supports specialized 'Agent Profiles' for defining distinct toolsets and memory states @Teknium.
Agentic Infrastructure
- Cloudflare tunnels are emerging as a superior alternative to ngrok for stable remote agent access @ivanleomk.
- New sandbox providers are achieving 60ms spin-up times by keeping snapshots local to the CPU and RAM @ivanburazin.
Models & Capabilities
- Gemini 3.1-Flash-Lite rivals much larger models in surprisingly strong knowledge benchmarks @teortaxesTex.
- Anthropic models now require manual cache write commands, impacting developer billing strategies @theo.
Reddit Dev Discussions
When API bills hit $4,000, the industry pivots from model obsession to 'context engineering' and structured memory.
The honeymoon phase of 'just hook up an LLM' is officially over. As we move into late 2025 and 2026, the narrative has shifted from the raw intelligence of the model to the grueling reality of orchestration. We are seeing a professionalization of the 'glue' layer—what practitioners are now calling 'context engineering.' Whether it is managing 4x budget overruns due to inefficient heartbeat settings or battling the 15% context growth seen in recursive loops, the challenge isn't finding a model that can think; it is building an infrastructure that doesn't go bankrupt while doing it.
Today's issue highlights this transition. We look at how Anthropic is attempting to solve the memory bottleneck with 'Dreams,' while the open-source community counters with sophisticated graph-based stores like Mem0. We also dive into the 'VRAM wall' where hardware choices are now strategic trade-offs between speed and massive context capacity. For those building in production, the consensus is clear: if you aren't engineering your context and memory as rigorously as your code, your agent is just an expensive experiment. Every token must be justified, and every memory must be managed.
Agent Teams are Becoming Context Engineering Teams r/AI_Agents
The industry is reaching a consensus that building agents is less about the LLM and more about the 'infrastructure mess' surrounding it. u/Antoneose argues that most teams are effectively becoming 'context engineering' teams, spending months solving orchestration glue rather than model performance. This infrastructure overhead is manifesting in massive production costs, with developers like u/Consistent-Arm-875 seeing 4x budget overruns due to heartbeat settings reloading full conversation histories. To combat this, builders are leveraging prompt caching, which can slash repeated input costs by 90%, although the initial 'cache write' requires a higher upfront premium.
Benchmarks show that for specific agentic tasks like cloud anomaly detection, Claude 3.5 is 22% cheaper than GPT-4o, costing $0.00087 versus $0.00112 for identical 512-token prompts Dev.to. Furthermore, practitioners are calculating a 15% context growth per loop in recursive agentic flows r/AI_Agents. To manage this, teams are adopting 'cheap model first' patterns, using Claude Haiku for 95% of tasks and only escalating to Sonnet on validation failure, a strategy that has successfully cut total spend by 70%.
Anthropic 'Dreams' vs. The Open-Source Memory Stack r/aiagents
Memory remains the primary bottleneck for agents performing long-running tasks, but the architecture is shifting from ephemeral context to structured persistence. Anthropic recently released 'Dreams' for Claude Managed Agents, a pipeline designed to clean memory stores across up to 100 session transcripts, which u/clawvault notes mirrors human memory consolidation. Meanwhile, open-source tools like Mem0 utilize hybrid graph and vector stores to outperform standard providers by 26% on accuracy, while agents themselves are demanding the ability to query their own history by relevance rather than receiving raw context dumps u/Huge_Opportunity4176.
Adversarial Debate Layers for Multi-Agent Consensus r/ArtificialInteligence
To prevent agents from going off-script, developers are moving toward structured adversarial architectures that gate high-stakes decisions. u/The_SpaceNerd debuted a five-agent debate layer—including roles like 'Devil's Advocate' and 'Sanity Checker'—to force articulation of disagreements, aligning with research showing role-based advocacy improves decision quality. However, u/Substantial_Step_351 warns that excessive critique steps can introduce small, embedded mutations that later agents fail to correct, leading to a pivot toward deterministic testing tools like AgentDiff.
Claude Security Beta and the Rise of 'Reasoning Crons' r/ClaudeAI
Anthropic has transitioned Claude Security into public beta, shifting code auditing from pattern-matching to reasoning-based data flow analysis. This system has been stress-tested by the Frontier Red Team and PNNL to defend critical infrastructure Cyberscoop. Alongside this, the launch of 'Claude Code Routines' is establishing 'reasoning crons' that allow developers to schedule autonomous tasks like nightly commit reviews and dependency checks u/EastMove5163.
AG-UI and the Standardization of Agent Frontends r/AI_Agents
Industry leaders are converging on the Agent-User Interaction (AG-UI) protocol to unify how typed events like tool calls and state updates are streamed to users. Supported by Google, Microsoft, and AWS, the protocol eliminates the need for custom adapters when switching between frameworks like LangGraph or CrewAI u/MorroWtje. This standardization is part of a broader consolidation where the Agent Communication Protocol (ACP) has merged into the A2A (Agent-to-Agent) protocol to streamline multi-agent coordination.
The VRAM Wall: Speculative Decoding and hardware r/LocalLLaMA
The RTX 5090 reaches 69.9 tok/s in raw inference, but the M5 Max dominates context capacity with 128GB of unified memory—effectively 4x the VRAM for massive reasoning tasks.
Meta ProgramBench: Offline System Synthesis r/MachineLearning
Meta's ProgramBench evaluates if AI can recreate complex programs like SQLite from scratch without internet access, pushing agents beyond simple snippet generation toward full-scale architecture.
NASA’s 'Power of Ten' Rules vs. AI Slop r/AI_Agents
Engineers are adopting NASA's 'Power of Ten' rules—such as limiting functions to a single page—to prevent the unmaintainable 500-line blocks often produced by frontier models.
Discord Tech Talk
OpenAI’s Operator and Anthropic’s MCP are formalizing the execution layer of the Agentic Web.
The industry is currently witnessing a tectonic shift from models that merely predict the next token to agents that navigate the web as human users do. Today’s lead story on OpenAI’s Operator signals the end of the brittle, DOM-scraping era, replaced by vision-driven systems that "see" and interact with UI elements in real-time. This isn’t just a novelty; it’s a fundamental change in how we build for the web, supported by new evaluation frameworks like BrowseComp that prioritize discovery over simple retrieval.
However, vision is only half the battle. For these agents to move beyond toy demos, they need a universal language and a reliable memory. Anthropic’s Model Context Protocol (MCP) is rapidly becoming the "USB-C for AI," providing the connective tissue between disparate enterprise data silos. Simultaneously, frameworks like LangGraph are solving the persistence problem, allowing agents to survive execution failures and human interruptions over long-running workflows.
For developers, the takeaway is clear: the stack is maturing. Whether it's Groq’s 800 token-per-second inference speeds making "Chain of Thought" loops viable or Ollama bringing tool-calling to local hardware, the infrastructure for production-grade agency is finally arriving. As we look at the sobering 32% success rate on hard benchmarks in AgentBench 2.0, it’s evident that while the tools are here, the engineering of reliable, autonomous reasoning remains our primary frontier.
OpenAI Operator and the Rise of Vision-Driven Web Automation
OpenAI's Operator marks a shift from 'thinking' to 'doing' by executing multi-step tasks directly within a browser environment, bypassing the need for structured APIs Aaron DiBlasi. To standardize performance evaluation for these systems, OpenAI has released BrowseComp, a benchmark specifically designed to test an AI agent's ability to locate hard-to-find information across complex web interfaces OpenAI.
While early developer reports highlight a 40% increase in task completion rates for complex workflows, independent researchers are now conducting head-to-head benchmarks against open-source leaders like browser-use to verify reliability in real-world scenarios r/AI_Agents. The core of this transition is a specialized vision-language model that interprets UI elements in real-time, effectively ending the era of brittle DOM-based scrapers AI-Weekly. However, as these agents scale, developers are identifying 'browser stealth' and anti-bot detection as the primary technical hurdles for production-grade deployments Browser Use.
MCP Solidifies Role as the 'USB-C for AI Tools' with 500+ Public Servers
The Model Context Protocol (MCP) has moved beyond its initial release to become a critical industry standard, effectively consolidating a once-fragmented tool-use landscape by providing a unified interface for agents. The ecosystem has seen an explosion in adoption, now surpassing 500 public servers that allow agents to seamlessly connect with enterprise data sources like Google Drive, Slack, and GitHub without requiring bespoke integration code VentureBeat. This standardized approach has reportedly led to a 40% reduction in integration time for developers, facilitating the rise of interoperable multi-agent systems that can share toolsets across different model frameworks NAXIA. Recent updates from Anthropic's technical staff highlight a 2026 roadmap focused on expanding this two-way communication standard to more complex enterprise data environments David Soria Parra.
LangGraph’s Persistence Layer Solidifies Stateful Multi-Agent Orchestration
LangGraph has codified the shift from rigid pipelines to cyclic, state-aware loops by introducing a robust persistence layer that utilizes checkpointers to save graph state to storage at every execution node. This architecture enables 'time travel' debugging and full state recovery, allowing agents to resume complex tasks even after failures or manual interruptions in workflows that persist over 24+ hour windows LangChain Docs. Developers are leveraging these primitives to implement advanced Human-in-the-Loop (HITL) patterns, where users can inspect and modify the agent's state mid-execution to ensure steerability in production environments Yash Sarode. By transitioning to explicit schemas and parallel execution nodes, teams are reporting improved reliability for multi-agent dependencies Sparkco AI.
Groq and Together AI Race for Agent-Speed Inference
Groq's LPU technology is delivering over 800 tokens/sec for Llama 3 8B, while Together AI targets sub-second TTFT to power the high-velocity "thought" cycles required for agentic reasoning.
AgentBench 2.0 and GAIA 2.0 Redefine Agentic Performance Standards
The release of AgentBench 2.0 and GAIA 2.0 reveals a performance gap where top-tier models maintain only a 32% success rate on hard tasks, highlighting the difficulty of translating coding prowess into general autonomy.
Ollama Empowers Local Agents with Native Tool Calling Support
Ollama has introduced native tool-calling for local LLMs like Mistral 7B and IBM Granite, enabling 100% data sovereignty for privacy-first agentic workflows on consumer hardware.
HuggingFace Research Logs
Brittle JSON tool-calling is out as 'smol' code-action frameworks and a benchmark trust crisis redefine agentic reliability.
The industry is hitting a 'reality wall' in early 2025, and the results are fascinating. For months, we have optimized for leaderboard rankings that, as it turns out, might be entirely hollow. A team from UC Berkeley just exposed that eight major agent benchmarks—including GAIA and SWE-bench—are effectively broken, with models scoring 100% without actually solving the underlying tasks. This 'trust crisis' is the catalyst for the shift we are seeing today: a move away from brittle, prompt-heavy architectures toward verifiable 'code-as-action' frameworks.
Leading this charge is Hugging Face’s smolagents, which replaces bloated JSON tool-calling with direct Python execution. The signal here is clear—minimalism is winning. By reducing logic steps by 30% and boosting performance by 26%, these 'smol' agents are proving that efficiency is the new scaling law. Meanwhile, NVIDIA and H Company are pushing the boundaries of what agents can actually do in the physical and digital worlds, prioritizing raw inference speed and spatial reasoning over parameter count. We are moving from agents that 'chat' to agents that 'operate,' and for developers, the transition from RAG to deep research and verifiable reinforcement learning is where the real value lies. Today's issue breaks down the frameworks, the benchmarks, and the specialized operators making this shift possible.
The 'Smol' Revolution: Code-Action Agents and MCP
Hugging Face is doubling down on the 'smol' philosophy with smolagents, a minimalist framework that replaces brittle JSON tool-calling with direct Python execution. This 'code-as-action' paradigm has demonstrated a 26% performance boost and a 30% reduction in logic steps compared to traditional multi-agent systems Hugging Face. The ecosystem's expansion into Tiny Agents demonstrates that fully functional, MCP-powered agents can be built in as few as 50 lines of code, providing a modular 'USB moment' for AI data connectivity.
While established frameworks like LangChain maintain a lead in scalability and community support, smolagents is rapidly closing the gap in execution efficiency and ease of use xpay. The robustness of this approach is evidenced by code-writing agents reaching 67% accuracy on the GAIA benchmark Hugging Face. This shift toward high-efficiency, code-native workflows arrives as 75% of large enterprises prepare to deploy agentic systems by 2026 Pooya.blog.
Integration with Vision-Language Models via smolagents-can-see and observability tools like Arize Phoenix Hugging Face further solidifies the framework for production-grade, multimodal navigation. This architectural pivot suggests that the future of the Agentic Web lies in direct code execution rather than the orchestration of static text prompts.
The Benchmark Trust Crisis: Bridging Industrial Reality and Evaluation Integrity
The movement toward industrial-grade AI agents is facing a critical 'trust crisis' as researchers expose the fragility of current evaluation metrics. A team from UC Berkeley recently demonstrated that eight major benchmarks—including GAIA and SWE-bench—can be exploited to achieve 100% scores without solving any actual tasks. This systemic failure highlights why IBM and UC Berkeley developed the IT-Bench and MAST frameworks to combat 'Incorrect Verification,' where agents declare victory despite failing the task, a factor contributing to a persistent 20% success ceiling in production IT environments according to @saurabh-jha.
High-Velocity Operators: Holotron-12B and the Future of GUI Agents
A new generation of specialized 'Computer Use' models is bridging the gap between static LLMs and dynamic desktop interfaces by prioritizing throughput over raw parameter count. H Company has released Holotron-12B, a multimodal agent engineered for production-scale GUI automation that achieves a staggering 8.9k tokens/s on a single H100 @Hcompany. This performance enables a 62.3% success rate on the ScreenSuite benchmark, nearly doubling the 36.1% baseline established by general-purpose models like Claude 3.5 Sonnet BenchLM.
NVIDIA Cosmos Reason 2: Bridging the Physical Reasoning Gap
NVIDIA has released Cosmos-Reason2, an open Vision-Language Model engineered as a planning engine for physical AI and robotics. Unlike previous iterations, this model integrates spatial-temporal understanding and a fundamental grasp of physics to navigate complex real-world scenarios NVIDIA. By utilizing long chain-of-thought reasoning, the model helps embodied agents determine sequential steps, effectively bridging the gap between digital logic and physical action NVIDIA.
Open Source Deep Research Reclaims the Web
Hugging Face's 'Open-source DeepResearch' project achieves 67% on GAIA by leveraging CodeAgent and SerpAPI to analyze hundreds of sources independently huggingface.
Agents.js: Bringing the Agentic Web to the Browser
The new Agents.js library eliminates the 'Python tax' for web developers, enabling multi-modal agent tools to run directly in JavaScript/TypeScript environments huggingface.
DeepSeek-V4: Million-Token Context for Agents
DeepSeek-V4 has launched with a native 1,000,000-token context window, significantly reducing RAG reliance for complex, multi-step agent operations DeepSeek.
Unlocking Agentic RL: LinkedIn’s Verifiable Training
LinkedIn's GPT-OSS shift focuses on verifiable outcomes rather than preference-based feedback, utilizing a closed-loop Agentic RL cycle LinkedIn.