The Great Agentic Execution Pivot
From OpenAI's Operator to Hugging Face’s smolagents, the industry is trading vibe-based chat for deterministic browser execution.
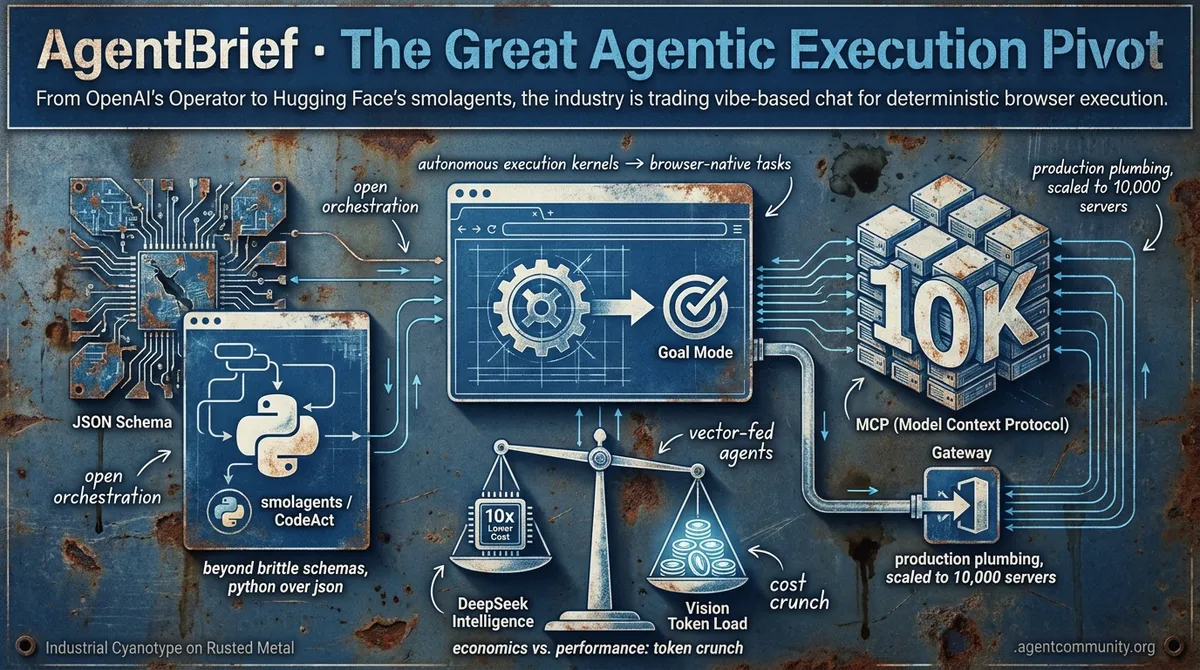
- The Execution Pivot OpenAI’s Operator and Goal Mode for Codex mark the definitive transition from conversational models to autonomous execution kernels capable of browser-native task completion.
- Standardizing the Stack Anthropic’s Model Context Protocol (MCP) has scaled to 10,000 servers, providing the necessary plumbing for agents to move beyond sandboxes into production-grade environments.
- Rebelling Against JSON Hugging Face’s smolagents and the CodeAct paradigm prioritize Python execution over brittle schemas, returning control and flexibility to agentic reasoning workflows.
- Economics vs. Performance While DeepSeek slashes intelligence costs by 10x, vision-based browser tools face massive token increases, forcing a hard rethink of production scaling and reliability.
with our friends at CraftHub
Craft Conference — June 4–5, 2026, Budapest — Two days of software craft talks at the Hungarian Railway Museum. Community discount included.
Get the discount →
X-Stream Dispatches
Stop prompting for answers; start building for objectives.
We are witnessing the final collapse of the "chatbot" era. This week’s developments signal a definitive pivot toward the agentic web, where the model is merely the engine and the harness is the actual product. OpenAI’s shift to autonomous "Goal Mode" for Codex isn't just a feature update; it’s a structural admission that long-running, local-environment-aware systems are the new baseline for developer workflows. For those of us building agents, the message from the community is clear: if you aren't investing in orchestration and persistent memory, you're building on sand. We're seeing frameworks like ReasoningBank finally tackle the 'agent amnesia' problem while tools like BrowserAct bypass API gatekeepers entirely by spoofing human behavior. But this autonomy comes with a heavy cost. The Composio breach is a sobering reminder that giving agents write-access to our infrastructure requires more than just a sandbox—it requires a total rethink of zero-trust architecture. Today, we look at why the symbiosis between model and harness defines the winner, why memory is finally scaling, and how to keep your autonomous workers from burning down the house.
OpenAI Codex Shifts to Autonomous Goal Mode
OpenAI has evolved Codex from simple code completions to long-running autonomous agents. According to @OpenAI, the new "Goal Mode" is available across the app, IDE, and CLI, allowing developers to set high-level objectives that agents can pursue for hours or even days. This transition from "answers" to "actions" is a fundamental shift in the developer workflow, as @freeCodeCamp emphasized.
The infrastructure now supports deep local integration, enabling Codex to securely control Mac applications from mobile devices even when the screen is locked @OpenAI. Builders like @petergyang called these features a "game changer," while @aakashgupta noted the power of parallel agent execution via OS-level sandboxing. This marks a move toward treating the Mac as a "multiplayer instrument" where agents and humans co-exist in the same OS environment.
For agent builders, this moves the goalposts for "local-first" automation. While early desktop details suggest default system-level sandboxing that limits agents to specific folders and branches @btibor91, users like @bnafOg highlight the ongoing need for kill-switches and more granular safety guardrails during multi-day tasks. The technical reality of managing agent state over long durations remains an active area of experimentation for the community.
The Era of the Standalone Model is Over
Top builders are reaching a consensus: model performance is no longer the primary differentiator for AI products. @gdb stated this explicitly, with @OfficialLoganK adding that the future belongs to the symbiosis between the model, the harness, and the product. This places a massive premium on orchestration layers that manage an agent's lifecycle and environment interaction rather than simple prompt hacks @LeoTava8.
This shift has ignited a debate over platform lock-in. @kunchenguid warned that proprietary harnesses like Claude Code often outcompete superior open-source alternatives primarily through subsidization. However, @emollick argues that labs will likely remain the sole providers of top-tier products because their control over post-training and access harnesses allows them to build specialized tools that third-party vendors cannot easily replicate.
Despite the lab advantage, specialized third-party tools are making significant gains. Pre.dev is reportedly outperforming Claude Code on Terminal-Bench 2.0 at 56.2% vs 53.9% @predotdev, while Hermes Agent from Nous Research is gaining traction for its self-learning loops and reliability @therobertta_. Builders are increasingly looking to flexible frameworks like LangGraph, CrewAI, and the Antigravity SDK to maintain control over their agentic workflows.
In Brief
Google Research Unveils ReasoningBank for Agentic Memory
Google Research is tackling "agent amnesia" with ReasoningBank, an Apache 2.0 framework that allows LLM agents to distill successful and failed trajectories into reusable reasoning strategies @DanKornas. By storing abstracted memory entries and retrieving them via embedding search, the system achieved an 8.3 point lift in success rates on WebArena and improved SWE-Bench Verified resolve rates to 57.4% @yaelkroy @AlphaSignalAI. As @teortaxesTex noted, this system turns raw experience into efficient inference-time signals, positioning it as critical infrastructure for persistent, self-evolving production systems.
Agentic Tool Compromise Leads to Composio Security Incident
The Composio security incident on May 21 serves as a stark warning about the risks of granting agents write-access to production environments @KaranVaidya6. An attacker exploited an internal agentic tool and escalated privileges via automated remediation systems, leading to the compromise of GitHub tokens and a total revocation of all user tokens as a precaution @composio. Observers like @PurpleOps_io highlighted how the attack specifically abused "self-healing" infrastructure to spread, prompting calls for zero-trust IAM and extreme sandboxing to prevent catastrophic blast radius events in autonomous systems @agentcommunity_.
BrowserAct: Free CLI Delivers Human-Like Browser Control
BrowserAct is democratizing human-like browser control with a free CLI that bypasses the need for expensive API keys or OAuth setups by leveraging the user's existing Chrome session @hasantoxr. The tool uses advanced anti-bot features like WebGL spoofing and canvas masking to solve CAPTCHAs and extract data from sites like LinkedIn, where users report pulling 50 leads in 10 minutes @browseract @ai_fied. With its "Skill Forge" feature auto-generating deploy-ready agent capabilities, it is being positioned by @AiSparks12 as a direct replacement for paid lead-gen services costing upwards of $99/month.
Quick Hits
Agent Frameworks & Orchestration
- PuzldAI offers a terminal-native framework for routing tasks and chaining agents across multiple LLMs @DanKornas.
- MAG Claude Plugins provides a marketplace for packaging agents and MCP integrations into workflows for Claude Code @DanKornas.
- Async Code Agent enables parallel execution of multiple coding tasks through a Codex-style web UI @DanKornas.
Models & Reasoning
- Recursive reasoning models like HRM and TRM are outperforming standard LLMs on Sudoku-Extreme using internal state updates @burkov.
- Gemini 3.5 Flash is showing significant post-training progress on GDPval, competing at the frontier @OfficialLoganK.
- New WebGPU backends are bringing high-performance ggml/llama.cpp support directly to the browser @ggerganov.
Agentic Infrastructure & Ops
- OpsKat acts as a natural-language ops agent for managing remote SSH servers and Kafka logs @DanKornas.
- AWS released a PQC Readiness Scanner to automate post-quantum cryptography assessments for TLS endpoints @amarchenkova.
- Daytona has built enterprise features like on-prem support and audit logs for agent environment management @ivanburazin.
Industry & Ecosystem
- Cursor has reportedly hit a $3B annual sales rate as rumors of a SpaceX acquisition circulate @rohanpaul_ai.
- Anthropic is on track for its first profitable quarter with Q2 revenue projected at $10.9 billion @CoinDesk.
Reddit Agent Intelligence
OpenAI moves beyond the chatbox to take over your browser with the new Operator preview.
2025 is officially the year of the agent. We have spent years talking to models; now, we are finally letting them do things. OpenAI's launch of Operator marks a definitive shift from conversational AI to deterministic execution kernels. It is not just about generating text anymore—it is about browser-level control and autonomous task completion. But as OpenAI pushes for the 'Computer-Using Agent' crown, the ecosystem is maturing simultaneously through competitive pricing and standardized plumbing.
DeepSeek is currently slashing the cost of intelligence by nearly 10x, making dense agentic loops financially viable for the first time. Meanwhile, Anthropic’s Model Context Protocol (MCP) has exploded to nearly 10,000 servers, providing the integration standard these agents need to access data reliably. For developers, the challenge is shifting from prompt engineering to architectural orchestration. From PydanticAI’s type-safe workflows to AutoGen’s event-driven overhaul, the tools are catching up to the vision. The era of 'vibe-based' development is ending; the era of production-grade agentic execution is here.
OpenAI Operator Launches: The CUA Model and the Shift to Autonomous Execution
OpenAI officially launched the research preview of Operator on January 23, 2025, signaling a pivot from conversational AI to the deterministic execution kernels discussed in recent industry reports. Powered by a new Computer-Using Agent (CUA) model, Operator is designed to independently control a web browser to execute long-horizon tasks like booking travel or managing online commerce. This development aligns with Sam Altman’s vision of 2025 as the 'year of agents' and addresses the 'execution gap' previously noted in frontier models.
By providing granular browser-level control, OpenAI aims to overcome the reliability issues that have led to high enterprise rollback rates, offering a standardized framework for autonomous tool-calling and state management. While the system is currently in research preview, it marks a significant escalation in the 'agentic web' arms race against Anthropic's computer-use capabilities. As noted by @TechCrunch, this release signals the move toward agents that perform tasks autonomously rather than just providing answers.
DeepSeek-V3 Challenges GPT-4o in Agent Logic r/LocalLLaMA
DeepSeek-V3 is aggressively challenging GPT-4o's dominance in agent logic by offering a 671B parameter MoE architecture at a disruptive $0.27 per 1M input tokens. This pricing makes the model 9.3x cheaper than GPT-4o, enabling high-volume agentic loops that were previously cost-prohibitive. While GPT-4o maintains a lead in native multimodal capabilities, DeepSeek-V3 has demonstrated superior performance on SWE-Bench Verified and AIME 2024, positioning it as a primary executor for deterministic software engineering workflows.
Anthropic MCP Hits 9,400 Servers as the Integration Standard r/mcp
Anthropic's Model Context Protocol (MCP) has scaled 7.8x year-over-year to reach over 9,400 servers, cementing itself as the n+m integration standard for AI data access. The ecosystem is moving beyond simple tool access toward sophisticated metadata discovery via 'MCP Server Cards' and specialized security scanners like Lurkr to audit for 'tool poisoning.' As the community takes over maintenance of reference servers, the focus for agent builders has shifted from finding tools to ensuring secure, production-grade connectivity as highlighted in r/aiagents.
PydanticAI: Bringing the 'FastAPI Feeling' to Agentic Workflows r/LangChain
PydanticAI aims to eliminate 'vibe-based' development by providing a production-grade framework built on strict Python type hints to validate tool calls and model outputs directly.
Microsoft AutoGen 0.4: Shifting to Asynchronous Architectures
Microsoft has overhauled AutoGen with a v0.4 release that pivots to a fully asynchronous, event-driven architecture to support distributed multi-agent reasoning loops at scale.
Browser-use Library: The 'Browser on a Leash' for Autonomous Navigation
The browser-use Python library is becoming the standard for granting LLMs direct control over web browsers via Playwright, enabling agents to execute complex multi-step workflows.
Discord Dev Dialogue
OpenAI's Operator and Anthropic's MCP are rewriting the agentic execution stack for production-grade autonomy.
Today marks a significant pivot in the agentic web: we are moving from agents that talk about tasks to agents that execute them natively within the browser and across standardized interfaces. OpenAI’s launch of Operator signals a direct challenge to the status quo, moving beyond simple chat to autonomous browser execution with high-success targets on procurement. But as we see with the rise of Anthropic's Model Context Protocol (MCP), the real battle isn't just about who can click buttons best—it's about how these agents talk to the rest of our stack.
For practitioners, the tension is clear. While native tools like Operator offer streamlined workflows, they face a 'reasoning ceiling' on complex OS-level tasks. Meanwhile, framework-level advancements like PydanticAI and LangGraph are hardening the 'agentic engineering' discipline, prioritizing type-safety and long-term state persistence over raw model capability. We are also seeing the cost of precision: Agentic RAG and vision-based browser tools offer massive performance leaps but at 10x to 45x the token cost. Today’s issue explores this balancing act between autonomy, interoperability, and the harsh reality of production economics.
OpenAI's Operator Signals Shift to Browser-Native Agents
OpenAI has officially launched Operator, a research preview for ChatGPT Pro users that marks a definitive pivot from conversational AI to autonomous browser execution. Unlike traditional LLMs, Operator utilizes a dedicated browser instance to navigate complex DOM structures, aiming for a 90% success rate on procurement tasks to surpass its current 87% benchmark on WebVoyager. While OpenAI claims Operator outperforms rivals like Google’s Mariner and Anthropic’s Computer Use, it still faces a significant "reasoning ceiling," scoring only 38.1% on the more rigorous OSWorld benchmark.
Developers are currently weighing Operator’s native integration against the high performance of the browser-use library, which holds a 78% success rate on complex browser tasks by combining vision and HTML parsing. A primary friction point remains latency and cost; while Operator streamlines workflows like travel booking, practitioners on r/OpenClawInstall note that visual interaction can be significantly more resource-intensive than API-first stacks. This transition necessitates a shift toward "agentic engineering," where session management and state persistence become as critical as the underlying model's reasoning capabilities.
Anthropic's MCP Registry and 'USB-C' Standard Solidify Agent Interoperability
Anthropic's Model Context Protocol (MCP) has solidified its position as the "USB-C for AI," moving beyond simple tool-calling to a universal interface that decouples tool logic from underlying models. The ecosystem is now powered by the MCP Registry, a centralized catalog and API that enables agents to dynamically discover and implement over 50 community-built servers, including specialized connectors for FileSystem navigation and Postgres databases. This standardization has reportedly led to a 40% reduction in boilerplate code for agentic pipelines, though the Cloud Security Alliance now maintains the "MCP Top 10 Security Risks" to address emerging vulnerabilities in tool-call payloads.
PydanticAI Hardens Agentic Engineering with Type-Safe Rigor
PydanticAI has solidified its position as the framework of choice for developers prioritizing "production-grade" reliability, offering a 65% reduction in runtime parsing errors by centering agent logic around Pydantic schemas. By ensuring that tool calls and outputs are validated natively through Python type hints, the framework provides a "lighter and more intuitive" dependency injection system than the feature-heavy LangChain ecosystem. Architecturally, PydanticAI differs from LangGraph by treating agents as high-level constructs defined by data schemas rather than explicit state machines, allowing developers to focus on data integrity over complex state management.
Browser-use Library Surpasses 12,000 Stars, Claude 3.5 Sonnet Emerges as Performance Leader
The browser-use library has surpassed 12,000 stars on GitHub, with Claude 3.5 Sonnet frequently cited as the top-performing model despite warnings that visual interaction can consume 45x more tokens than API-based architectures.
LangGraph Persistence Hardens Agentic Memory for High-Concurrency Production
LangGraph is moving toward PostgreSQL and Redis checkpointers to ensure durability and context persistence across weeks of inactivity, critical for human-in-the-loop workflows.
Agentic RAG: The 42% Precision Leap Comes with a 10x Cost Trade-off
Transitioning from static retrieval to Agentic RAG architectures like 'Self-RAG' is yielding a 42% precision lift, though at the cost of 3-10x the token usage compared to standard pipelines.
HuggingFace Open Source
Hugging Face's minimalist 'smolagents' rejects JSON-jail as NVIDIA pushes VLMs into the physical world.
Today's release of 'smolagents' by Hugging Face marks a definitive pivot in the agentic stack: we are witnessing a rebellion against 'JSON-jail.' For too long, developers have wrestled with brittle schemas and heavy abstractions that stifle the inherent reasoning capabilities of LLMs. By embracing 'CodeAct'—where the agent’s primary action is writing and executing Python—we are returning to a more flexible, minimalist architecture that prioritizes logic over boilerplate. This is a crucial move for practitioners who need transparency and control over autonomous workflows. But this shift toward leaner frameworks comes at a time when the stakes for reliability are higher than ever. While smolagents simplifies the 'how' of building, new research from IBM and UC Berkeley highlights the 'why' of current failures, citing a sobering 5.3 failure modes per trace in long-horizon tasks. Simultaneously, NVIDIA is pushing the boundaries of throughput with Holotron-12B, aiming to eliminate the 'pixel-to-action' latency that has historically crippled GUI agents. We are moving toward a world where agents are either incredibly lightweight and code-centric or specialized, high-velocity operators grounded in physical reality. For practitioners, the message is clear: the most effective agents won't just follow instructions; they will write the software they need to succeed in real-time.
smolagents: Orchestrating Agents via Raw Python Code
Hugging Face has launched smolagents, a minimalist library of approximately 1,000 lines Hugging Face that shifts away from complex abstraction layers in favor of agents that write and execute Python code. By treating 'code as the action' (CodeAct), these agents leverage LLMs' inherent programming capabilities to handle complex logic, a method that recently helped their Transformers Code Agent achieve a 67% success rate on the GAIA benchmark Hugging Face. The ecosystem is expanding rapidly with VLM support and integration with Arize Phoenix for tracing.\n\nSecurity is a core focus, with the framework offering multiple execution paths to mitigate the risks of running LLM-generated code. While it includes a LocalPythonExecutor, Hugging Face explicitly recommends remote execution via E2B, Docker, or Blaxel (executor_type='blaxel') to provide robust security isolation Hugging Face Docs. This move away from 'JSON jail' allows for more flexible tool composition compared to heavyweight frameworks, enabling developers to build MCP-powered agents in as few as 50 lines of code.
Vision-to-Action: High-Throughput VLMs and the End of GUI Latency
The 'Computer Use' segment is shifting from general-purpose reasoning to high-velocity execution, led by Holotron-12B. Developed by Hcompany and NVIDIA, this model achieves a staggering throughput of 8.9k tokens/s on a single H100, effectively bridging the 'pixel-to-action' latency gap. Diagnostic benchmarks from ScreenSuite show specialized operators hitting a 62.3% success rate floor, nearly doubling the 36.1% baseline set by general-purpose LLMs. To move these agents into production, the community is deploying ScreenEnv, a full-stack framework for reproducible desktop agents, alongside the Holo1 family powering the Surfer-H agent.
The Science of Failure: New Agent Benchmarks
IBM Research and UC Berkeley are shifting the focus from 'vibe checks' to systematic failure analysis through the Open Agent Leaderboard. Diagnostic data from the VAKRA analysis reveals a sobering reality: even advanced agents average 5.3 failure modes per trace during long-horizon planning, with errors particularly costly in production where tool-calling failure rates range between 3-15%. The IT-Bench and MAST frameworks diagnose performance in complex IT automation, while AssetOpsBench focuses on agents managing physical and digital assets where failure rates can exceed 30%.
Open-Source DeepResearch: The Rise of LangGraph-Orchestrated Autonomy
Hugging Face's Open-source DeepResearch initiative is democratizing long-horizon search and synthesis by utilizing a hierarchical subagent architecture. Technical implementations confirmed that these agents are largely built on the LangGraph framework, managing complex state transitions to achieve a #6 ranking on the Deep Research Bench Leaderboard with a performance score of 0.4344. The scalability of these workflows is supported by DeepSeek-V4, which offers a 1 million token context window to maintain 'memory' of research objectives over long horizons.
Unified Tools and Intel-Powered Local Acceleration
The Unified Tool Use initiative has established a standardized schema that allows portable tool definitions across Mistral, Cohere, and Llama models via automatic schema conversion.
Intel Core Ultra Optimization
Intel has significantly reduced 'agentic' latency on Core Ultra processors by pruning 6 out of 28 layers from a Qwen3-0.6B draft model to optimize speculative decoding for tool-calling.
NVIDIA Cosmos and the Physical Agent
NVIDIA Cosmos Reason 2 introduces improved spatio-temporal understanding and a 256K context window NVIDIA AI to bridge visual perception and physical action for robotics.
EHR Navigator Specialization
The EHR Navigator Agent demonstrates vertical specialization by leveraging MedGemma to autonomously navigate complex electronic health records via structured FHIR data.