Reasoning Collapses, Action Scaling Begins
DeepSeek-R1 resets the cost of intelligence while OpenAI’s Operator turns pixels into production actions.
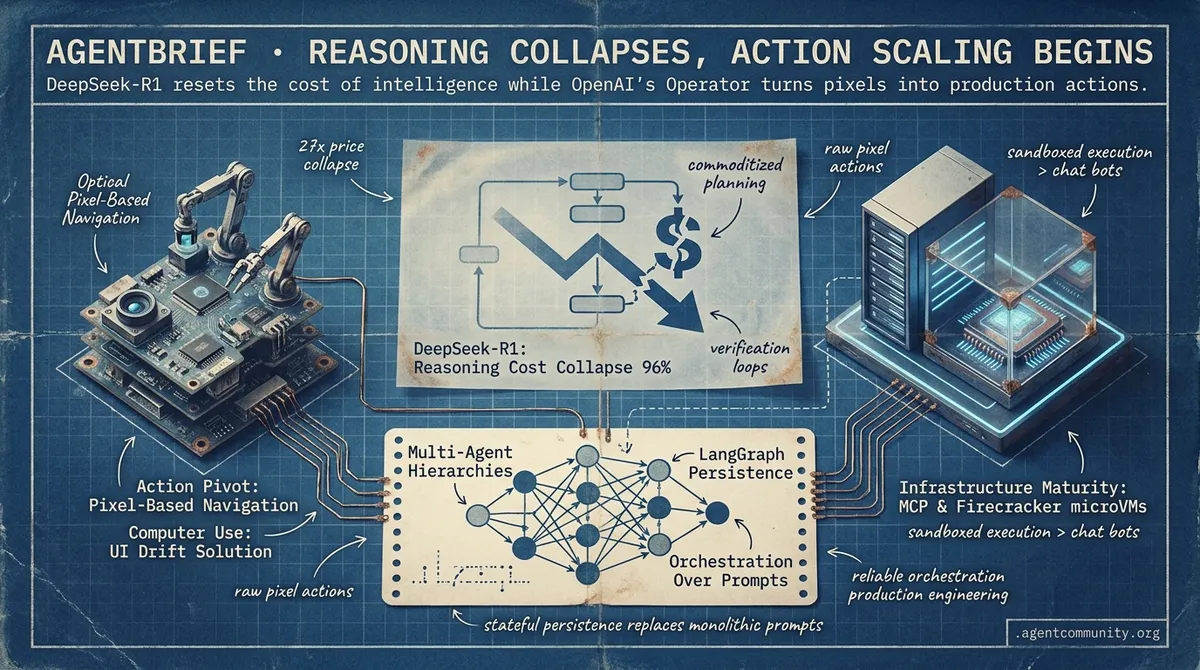
- Cheap Reasoning Shift DeepSeek-R1 has collapsed reasoning costs by 96%, commoditizing high-level planning and verification loops for agentic workflows.
- The Action Pivot OpenAI’s Operator and Anthropic’s Computer Use are moving agents beyond brittle APIs and into raw pixel-based navigation to solve UI drift.
- Orchestration Over Prompts Multi-agent hierarchies and stateful persistence in LangGraph are replacing monolithic prompts as the industry standard for reliability.
- Infrastructure Maturity From MCP’s 10,000+ servers to sandboxed execution in Firecracker microVMs, the ecosystem is shifting from 'chat bots' to production engineering.
with our friends at CraftHub
Craft Conference — June 4–5, 2026, Budapest — Two days of software craft talks at the Hungarian Railway Museum. Community discount included.
Get the discount →
Reddit Pulse
DeepSeek-R1 collapses the cost of reasoning while OpenAI’s Operator turns pixels into actions.
We have reached a definitive pivot point in the development of the Agentic Web. For months, the primary bottleneck for autonomous systems was the prohibitive cost and latency of high-level reasoning. With the release of DeepSeek-R1, that barrier has effectively evaporated. A 96% price reduction compared to OpenAI’s o1 isn't just a discount; it is a phase shift that allows practitioners to embed dense reasoning loops—planning, self-correction, and verification—into production workflows without bankrupting their projects.
But brains are useless without hands. OpenAI’s 'Operator' and the rise of Computer-Using Agent (CUA) models signify a move past the API-only era. We are now teaching agents to navigate the web through raw pixels, solving the 'UI drift' that has long plagued traditional automation. Combined with the explosion of the Model Context Protocol (MCP) ecosystem, which now boasts over 10,000 servers, the infrastructure for agents to 'see' and 'do' is finally catching up to their ability to 'think.' Whether you are building state-machines in LangGraph or local-first agents with Ollama, the cost of intelligence is trending toward zero, while the surface area for action is expanding to the entire web.
DeepSeek-R1: Commoditizing Reasoning and the 27x Price Collapse
The release of DeepSeek-R1 has fundamentally altered the cost structure of agentic workflows, offering reasoning performance that matches OpenAI's o1 at 1/27th the cost [Vellum]. This 96% price reduction enables high-latency reasoning steps—such as long-horizon planning and self-correction—to be embedded in production loops without the prohibitive overhead of proprietary models.
Unlike its closed-source rivals, R1's open-weight architecture allows for local deployment and weight inspection, solving a critical privacy hurdle for enterprise agents [Galileo]. While R1 excels on logic-heavy benchmarks like AIME 2024 and MATH-500, matching or exceeding o1-preview, it shows specific limitations in 'sentence-level' reasoning and citation accuracy where OpenAI still maintains a narrow lead [UMBC].
Furthermore, the rapid release of distilled variants—ranging from 1.5B to 70B parameters—has enabled developers to run high-quality reasoning on consumer-grade hardware [DataCamp]. However, the release has sparked controversy over whether DeepSeek distilled o1's outputs to achieve these gains, a claim that highlights the intensifying competition in the reasoning model sector.
OpenAI Operator and the Rise of the Computer-Using Agent (CUA) Model
OpenAI's launch of 'Operator' marks a definitive shift toward the Computer-Using Agent (CUA) model, which independently executes web actions via a specialized perception-reasoning-action cycle [Anchor Browser]. This paradigm allows agents to navigate virtual browsers and interact with GUI elements directly, effectively dissolving the barrier to automating legacy software that lacks native APIs. Practitioners are finding that these visual-first agents handle UI drift—the primary cause of failure in traditional automation—an order of magnitude better than previous systems [ACTGSYS], though safety concerns regarding autonomous form-fills remain a key focus for sandboxed deployments.
LangGraph vs. CrewAI: The Orchestration Paradigm Split
The ecosystem for agent orchestration has bifurcated into two distinct camps: state-machine architectures like LangGraph and role-playing frameworks like CrewAI [GuruSup]. LangGraph currently leads the enterprise sector by offering fine-grained control over cycles and state persistence, while CrewAI maintains a strong following for rapid prototyping through its 'manager-worker' hierarchy [Meta-Intelligence]. As the industry moves away from 'vibe coding,' both frameworks have integrated vector-based episodic storage to allow agents to retain context across disparate sessions and prevent the 'context rot' previously noted in long-horizon tasks [IBM Developer].
MCP Ecosystem Surpasses 10,000 Servers as 'Agentic Tunneling' Goes Mainstream
Anthropic's Model Context Protocol (MCP) has crossed the 10,000 server milestone, introducing 'Agentic Tunneling' to securely bridge local environments with cloud-based services [@instatunnel].
AgentOps and the Shift to Trajectory-Based Evaluation
Tools like AgentOps and Opik are replacing 'vibe checks' with trajectory-based evaluation, scoring the entire execution path of an agent to debug failures in complex multi-step workflows [LangChain].
Ollama and Llama.cpp Enable Privacy-First Local Agents r/LocalLLaMA
Ollama v0.3.0+ has introduced native tool calling support, enabling sub-50ms latency for local agents executing functions on consumer-grade hardware [u/meirgotroot].
Discord Dispatch
From 100% state persistence to 81% coding benchmarks, autonomous systems are finally growing up.
The industry is currently moving past the 'chat box' era of AI, pivoting toward systems that actually perform multi-step work with reliability. Today's synthesis highlights a massive push into stateful orchestration and UI-level interaction. We're seeing LangGraph drive a shift where 75% of enterprise pilots prioritize shared memory, ensuring agents don't just forget who they are the moment a server restarts. Meanwhile, Anthropic’s 'Computer Use' is setting a new standard for how agents navigate the software we use every day, doubling previous performance on OSWorld benchmarks. For developers, the message is clear: the 'inner loop' is getting faster and more local with Llama 3.1, while the 'outer loop' is getting smarter and more deliberative with MCTS. We aren't just building faster bots; we're building autonomous systems with 'time travel' debugging and zero-trust security. This issue dives into the infrastructure making that possible, from the 81% success rates on SWE-bench Verified to the emerging 'Agentic AI Fault Taxonomy' that helps us understand why these systems fail. As we move from simple ReAct loops to search-based reasoning, the focus shifts from speed to reliability—a necessary trade-off for high-stakes production environments.
LangGraph Checkpointers Enable Robust Agent Persistence
The industry is rapidly shifting toward stateful agent orchestration, driven by LangGraph’s advanced checkpointing which enables 100% state persistence across complex, multi-step workflows Kalvium Labs. This persistence layer allows agents to survive server restarts and handle asynchronous user feedback by saving snapshots of the graph state at every step LangChain Docs. Crucially, the 'time travel' capability lets developers pause, inspect, and rewind agent states, a feature that has become essential for debugging non-deterministic behaviors in production AlphaBOLD.
Adoption of graph-based architectures has surged, with 75% of enterprise pilots now prioritizing shared memory and coordination over simple linear chains DataNorth. For high-concurrency environments, the focus has moved toward PostgreSQL and Redis checkpointers, ensuring context persistence across weeks of inactivity Appri AI. This infrastructure is particularly vital for 'human-in-the-loop' approvals, where agents must wait for human intervention without losing execution context Apify.
Claude Computer Use API Redefines UI Automation
Anthropic's 'Computer Use' capability for Claude 3.5 Sonnet has emerged as the first frontier model to offer public beta GUI interaction, allowing agents to manipulate cursors and interpret screenshots natively Anthropic. The model achieved a 14.9% success rate on the OSWorld benchmark, nearly doubling the performance of existing AI models, though it still faces a 'reasoning ceiling' in complex environments. To combat the 5-10 second latency per action, developers are increasingly pairing vision with accessibility tree parsing to reduce token costs and improve precision vision-pro. This shift represents a fundamental pivot toward teaching agents to use computers like humans rather than relying on restricted API integrations Hacker News.
SWE-bench Verified Scores Surge to 81% as "Pro" Benchmarks Tighten the Gap
The landscape of autonomous coding has shifted from the original 4% baseline to a new reality where top-tier agents are resolving up to 81% of issues on the SWE-bench Verified subset Morph. This leap is exemplified by systems like mini-SWE-agent, which reportedly achieves a 74% success rate using only 100 lines of Python code SWE-bench. However, the community is moving beyond these curated scores toward more rigorous evaluations like SWE-bench Pro, where the highest current performance sits at 46%, highlighting a significant reasoning gap between isolated tasks and raw GitHub issues Scale Labs.
MCTS for Agents: Moving Beyond Simple ReAct
Search-based reasoning is evolving from reactive loops toward MCTS architectures, achieving a 22% reduction in redundant API calls by pruning ineffective paths early research-lead.
Llama 3.1 8B Bridges the Gap Between Edge Speed and Tool Precision
Llama 3.1 8B is emerging as a premier 'edge brain' for agents, clocking 120 tokens/sec and rivaling GPT-4o-mini with 90% tool-calling accuracy AIMLAPI.
Zero-Trust Sandboxing Becomes Standard for Tool Use
To mitigate RCE risks, the industry is adopting Zero-Trust stacks using Wasm for Python tool isolation or Firecracker microVMs for hardware-level security Microsoft Security Blog.
HuggingFace Highlights
Small models are escaping 'JSON jail' while hierarchical orchestration hits the 50-agent scaling wall.
We are witnessing a fundamental decoupling in the agentic stack. The era of throwing a massive prompt at a frontier model and hoping for the best is over; today’s landscape is defined by hierarchy, specialized tool-use, and active memory management. Frameworks like Microsoft AutoGen and CrewAI are proving that a 'manager' agent delegating to specialists isn't just a neat trick—it’s a performance necessity, yielding 40% improvements in complex tasks. Meanwhile, the 'bigger is better' mantra is being challenged at the edge. 7B and 8B models are now outperforming giants on the Berkeley Function Calling Leaderboard by focusing on precision over parameters. For builders, the message is clear: the bottleneck isn't just reasoning; it's orchestration, secure execution, and the 'verification gap.' Whether it's sandboxing code in Firecracker microVMs via E2B or implementing asynchronous Human-in-the-Loop patterns in LangGraph, the 'Agentic Web' is becoming an engineering discipline rather than a prompting dark art. We are moving from static reasoning to autonomous systems that can navigate browsers, manage their own virtual memory, and—crucially—know when to ask for help.
Beyond Monolithic Prompts: The Rise of Hierarchical Multi-Agent Orchestration
Frameworks like Microsoft and CrewAI are fundamentally redefining autonomous workflows by moving away from brittle, single-model prompts toward collaborative, multi-agent systems. Recent benchmarks confirm that hierarchical structures—where a designated 'manager' agent delegates sub-tasks to specialized workers—yield a 40% improvement in task completion for complex coding and research trajectories. While Microsoft AutoGen is currently ranked as the premier framework for complex, event-driven systems, CrewAI is favored for its role-based automation capabilities f3fundit.
As these systems scale toward enterprise production, performance bottlenecks are becoming a critical focus for developers. Engineering audits in 2026 highlight that while custom orchestration is often required for high-security environments, frameworks like LangGraph are increasingly used to manage complex state transitions in production tensoria. However, practitioners are warned of a "scaling wall" where many standard orchestration frameworks begin to experience logic degradation when managing more than 50 concurrent agents orchestrai. This shift underscores the industry's move toward modular, verifiable agent architectures.
Beyond Context Windows: The Rise of Agentic Memory
Architectures are shifting from passive retrieval to active memory management to overcome the limitations of static context windows, even as they expand to 1M+ tokens. Inspired by MemGPT, which mimics an operating system's virtual memory, new implementations like A-Mem allow agents to autonomously move information between main context and external storage. Research indicates these 'agentic' memory hierarchies can reduce hallucination rates by 25% in long-running sessions, effectively bypassing the 'lost in the middle' phenomenon seen in models like DeepSeek-V4.
Precision Over Scale: 7B Models Challenge Giants in Tool Use
Specialized 7B and 8B models are now challenging frontier giants on the Berkeley Function Calling Leaderboard (BFCL) V4 by focusing on precise schema adherence. Research shows that models like Gorilla-OpenFunctions-v2 and Nexusflow-Raven-v2 can significantly outperform general-purpose models ten times their size. This pivot toward 'Tool-Augmented Language Models' has reduced parameter hallucination rates by 35% in complex multi-turn environments, proving that 'JSON jail' can be escaped through fine-tuning rather than raw scale.
Refining Human-in-the-Loop Patterns for Production
Human-in-the-Loop (HITL) patterns are coalescing into a primary governance model to bridge the 'verification gap' in high-stakes production environments. Utilizing frameworks like LangGraph and smolagents, developers are implementing 'interrupt and resume' patterns that increase user trust by 60% Hugging Face. These systems prioritize three elements—timely context, explicit authority, and a defensible rationale—allowing humans to steer agents without breaking execution state.
Securing the Sandbox: Firecracker microVMs and the E2B Standard
Infrastructure providers like E2B are setting the security standard by using Firecracker microVMs for hardware-level isolation of agent-generated code execution.
From Static Reasoning to Agentic Autonomy: The Benchmark Shift
New gold standards like GAIA and SWE-bench Verified are exposing a 'performance cliff' where models frequently score below 30% on complex multi-step web tasks.