Production Agents: The Era of Standardized Reliability
From stateless demos to stateful systems, the agentic stack is maturing through MCP and persistent orchestration.
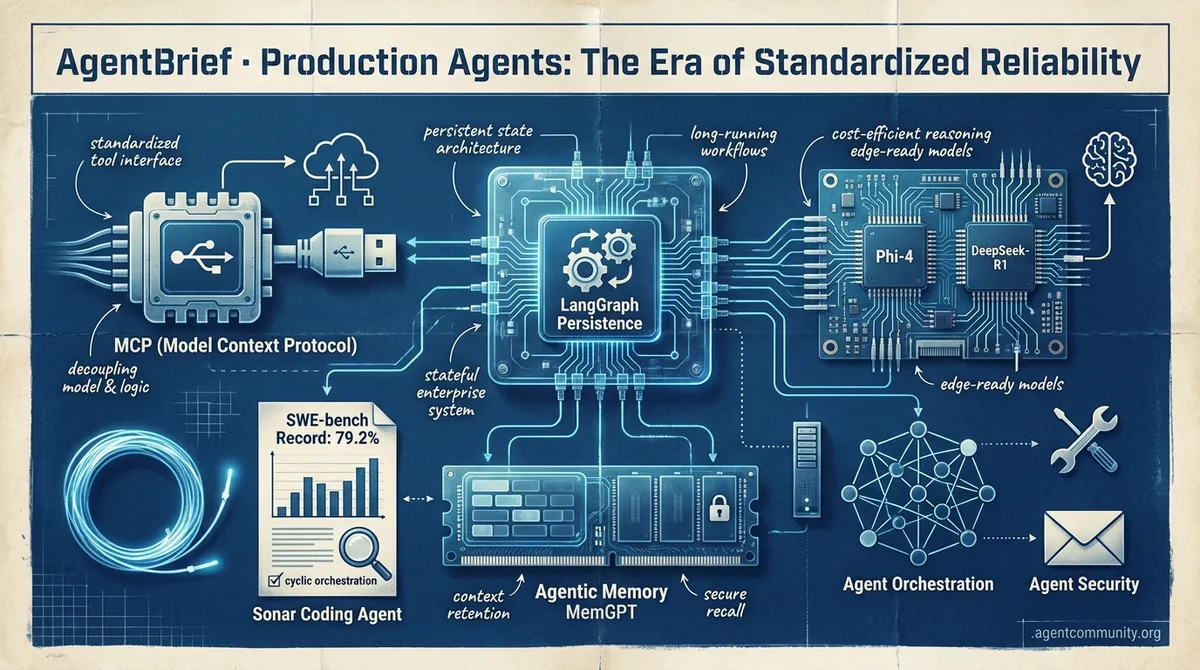
- Standardizing the Stack Anthropic’s Model Context Protocol (MCP) is emerging as the 'USB-C' of AI, decoupling tool logic from model APIs to solve the enterprise integration nightmare.
- Beyond Stateless Demos The industry is shifting from fragile prompt-engineering to stateful systems architecture, with LangGraph and MemGPT leading the charge in persistent, long-running workflows.
- Coding Benchmark Breakthroughs Autonomous coding agents are smashing SWE-bench records, with Sonar reaching a 79.2% solve rate by leveraging cyclic orchestration and self-healing execution loops.
- The Reasoning War The frontier has moved from raw performance to production economics, as edge-ready models like Phi-4 and cost-efficient challengers like DeepSeek-R1 redefine the 'agent brain.'
with our friends at CraftHub
Craft Conference — June 4–5, 2026, Budapest — Two days of software craft talks at the Hungarian Railway Museum. Community discount included.
Get the discount →
X Insights
Stateless chains are for demos; stateful graphs are for the enterprise.
We are moving past the era of stateless prompt-engineering and into the era of agentic systems architecture. For those of us building the agentic web, the focus has shifted from 'can the LLM do this?' to 'can the system recover when the LLM fails?' Reliability is the new frontier. This week, we’re seeing the scaffolding of the production-grade agent take shape. LangGraph’s pivot to stateful persistence isn't just a feature update; it’s an admission that complex, long-running workflows can’t survive on stateless chains. Meanwhile, the battle for the 'agent brain' is heating up between GPT-4o and Claude 3.5 Sonnet, proving that raw speed is useless if the reasoning falls off a cliff. We’re also seeing infrastructure catch up, with Together AI and Groq racing to eliminate the latency bottlenecks that kill agentic flow. If you're shipping agents today, you're no longer just a prompt engineer—you're a distributed systems architect. Today’s issue dives into the tools and trade-offs defining that shift.
LangGraph Persistence Unlocks Stateful Enterprise Agents
LangChain has officially pivoted LangGraph into a core focus, prioritizing robust stateful persistence for production-grade AI agents. As noted by @hwchase17, this capability allows agents to maintain context across restarts, enabling complex human-in-the-loop workflows that were previously too unstable for enterprise use.
The community reaction highlights a fundamental shift in architecture. Builder @erikschluntz argued that transitioning from stateless chains to stateful graphs is the only viable path for building reliable agents capable of multi-hour or multi-day tasks. Furthermore, @charles_irl demonstrated how these checkpoints enable 'time-travel' debugging, allowing developers to rewind an agent's state to fix logic errors mid-execution.
For agent builders, this changes the game by providing 100% state persistence via state-machine control, a metric where LangGraph is reportedly outperforming rapid-prototyping alternatives like CrewAI in production @agentcommunity_. Emerging best practices include using PostgresSaver with interrupt_before for approval gates and TypedDict to prevent state conflicts @sauvast @NullS0S.
Looking ahead, the release of LangGraph 1.2.0 has added durable error-handler resumes, significantly strengthening fault tolerance for long-horizon tasks @aginaut. This move signals that the 'agentic web' will be built on durable, resumable state machines rather than ephemeral API calls.
GPT-4o Tool Calling: Speed Gains vs. Reliability Trade-offs
The release of GPT-4o introduced native tool-calling optimizations designed to reduce latency in multi-turn agentic cycles. However, the speed gains come with significant caveats; @ItakGol reported a 20% degradation in reasoning, coding, and math benchmarks, with the model scoring only 640/980 compared to the ~800 achieved by GPT-4 Turbo.
Builders are divided on whether the lower latency justifies the intelligence dip. @jijosunny observed GPT-4o underperforming across various tasks with increased hallucinations, describing it as a faster but inferior model. In high-stakes environments, @toms_dome noted that while GPT-4o's function calling is reliable for trading signals, its weaker reasoning remains a bottleneck.
In the broader agent landscape, Claude 3.5 Sonnet is emerging as a formidable competitor. @SJackson56484 found Sonnet superior for autonomous tool calling, offering low latency without sacrificing the reasoning capabilities required for complex autonomy. This suggests that for many builders, the 'winning' model is defined by trajectory efficiency rather than raw token speed.
Ultimately, the data suggests that raw speed is a secondary metric for complex agents. As @HarperEFoley emphasized, an agent completing a task in 8s vs 14s matters less than the accuracy of the final trajectory, especially when vision-based multimodal tasks are involved.
In Brief
CrewAI Sequential Memory Update Released
CrewAI has introduced a major update to its memory layer to enable shared context across specialized agent teams, a move that @joaomdmoura claims significantly reduces context drift during long-running tasks. This update allows manager agents to reference previous failures to improve delegation success, as verified by @m_p_h_. While builders like @surajk_umar01 see this as critical infrastructure to combat 'long-term amnesia,' others such as @vibecoding_app note that production-scale scaling still faces hurdles compared to graph-based frameworks.
Together AI Launches Turbo Inference for Agents
Together AI's new Turbo Inference endpoints target high-frequency agentic loops with a claimed 3x reduction in time-to-first-token for Llama 3 models @togethercompute. This low-latency infrastructure is vital for real-time applications like customer support, according to @vincenzolomonaco, and complements the rollout of Qwen3.7-Max for complex orchestration @togethercompute. However, the broader community notes that raw inference speed is only half the battle, as techniques like MCTS pruning are still needed to reduce redundant calls by 22% and resolve deeper orchestration bottlenecks @agentcommunity_.
Quick Hits
Agentic Tooling & UX
- Mistral 7B v0.3 now includes native tool-calling support for edge-based agent capabilities @mistralai.
- Vercel AI SDK adds generative UI support, allowing agents to render components mid-stream @shadcn.
Inference & Performance
- Groq achieves 800 tokens/sec on Llama 3 8B to eliminate planning bottlenecks @groqinc.
- DeepSeek-V2 outperforms open-weight rivals in code-generation for tool definitions @deepseek_ai.
Reddit Roundup
From experimental copilots to autonomous contributors, agents are finally clearing the SWE-bench hurdle.
We are witnessing the death of the 'one-shot' agent. For months, the narrative around AI agents was dominated by high-latency, fragile loops that crumbled at the first sign of a real-world repository. Today, that narrative is shifting. The latest results from the SWE-bench leaderboard—where Sonar is now claiming a staggering 79.2% solve rate on verified tasks—suggest that we have moved past the 'hallucination of logic' phase.
This isn't just about bigger models; it is about the architecture of autonomy. Whether it is the rise of cyclic orchestration in frameworks like LangGraph or the move toward OS-inspired 'agentic memory' seen in projects like MemGPT, the focus is squarely on the execution loop. We are seeing agents that can run their own unit tests, manage their own context windows like RAM, and navigate the web through a hybrid of vision and DOM processing. For builders, the message is clear: the frontier isn't just a smarter LLM; it is a more resilient system that knows how to reflect, remember, and recover. This issue explores the tools and frameworks making this shift possible, from 8B powerhouses to sandboxed security protocols.
Autonomous Coding Agents Smash SWE-bench Records r/MachineLearning
The landscape of software engineering agents has transitioned from experimental 'copilots' to 'autonomous contributors' capable of handling complex repository-level tasks. While Devin initially set a high bar by resolving 13.86% of real-world issues unassisted on the SWE-bench Full dataset, newer benchmarks show an explosive performance jump. Sonar recently claimed the top spot on the SWE-bench Verified leaderboard with a record-breaking 79.2% solve rate, while also hitting 52.62% on the Full dataset.
This shift is mirrored in the open-source community, where OpenDevin (now OpenHands) introduced CodeAct 1.0, achieving a 21% solve rate on SWE-Bench Lite unassisted. Beyond raw solve rates, practitioners are focusing on the 'execution loop' to solve the 'hallucination of logic' problem. Modern agents like mini-SWE-agent demonstrate that high performance (up to 74% on Verified) can be achieved with compact, 100-line Python loops that prioritize deterministic tool usage. As noted by r/MachineLearning, the key to production reliability is the agent's ability to run its own unit tests and iterate based on execution feedback rather than just token prediction.
Beyond Vector Search: The Rise of Agentic Memory r/ArtificialInteligence
Static vector databases are proving insufficient for agents that must learn and adapt over time, leading to the rise of OS-inspired architectures like MemGPT and Mem0. These systems treat the context window as RAM and external databases as a disk, allowing agents to autonomously decide what information to keep in 'main memory' and what to offload to prevent the 'babysitting' problem. Performance data suggests that these hierarchical memory structures—combining episodic and semantic stores—can yield a 45% improvement in context relevance over standard RAG systems, according to discussions on r/ArtificialInteligence.
The Vision-DOM Hybrid for Web Automation Reliability r/LLMDevs
The paradigm for autonomous web navigation is shifting from brittle DOM-based scraping to a hybrid 'Vision-Language-Action' (VLA) approach. Frameworks like Skyvern and Browser Use leverage computer vision to interpret web layouts, allowing them to bypass traditional 'anti-bot' measures and adapt to dynamic UI shifts. While leading agents on the Halluminate Web Bench are achieving 81% reliability, developers on u/LLMDevs emphasize that while vision provides the 'sense' of the page, deep DOM access remains the 'real differentiator' for ensuring deterministic execution in production environments.
Beyond Linear Chains: The Rise of Cyclic Graphs
Frameworks like LangGraph and CrewAI are shifting the industry away from 'one-shot' linear chains toward cyclic agentic workflows. These architectures prioritize reflection and state management, patterns that have become essential for reaching 92% accuracy in complex tasks. This shift is a direct response to research identifying state management failures as the primary cause of multi-agent system collapse, leading developers to adopt 'checkpointing' and specific 'Handoff' patterns as seen on ITNext.
The Rise of the 8B Powerhouse r/LocalLLaMA
Specialized sub-10B models like Llama-3-8B and Phi-3-mini are now hitting parity with frontier models in single-turn tool-calling tasks on the Berkeley Function Calling Leaderboard r/LocalLLaMA.
Securing the Agentic Web
Indirect Prompt Injection (IDPI) has emerged as the #1 risk for 'computer-using' agents, necessitating sandboxed execution and instructional hierarchies to prevent hidden command exploits @RuhAI.
Discord Digest
Anthropic’s protocol emerges as the 'USB-C' for agents while production frameworks shift toward state-machine persistence.
Today’s agentic landscape is shifting from experimental chatbots to hardened autonomous systems, with a clear focus on reliability and standardization. Anthropic’s Model Context Protocol (MCP) is rapidly becoming the industry’s 'USB-C,' promising to solve the integration nightmare that has long plagued enterprise deployments. By decoupling tool logic from model APIs, developers are finally seeing a path out of the 'n+1' integration problem that slows down production cycles.
But standardization is only half the battle; orchestration is maturing in parallel. We are seeing a distinct divide between the heavyweight, stateful control of LangGraph—now prioritized by 75% of enterprise pilots—and the minimalist, decentralized handoffs pioneered by frameworks like OpenAI’s Swarm. Meanwhile, the 'reasoning wars' have moved from frontier performance to production economics, as DeepSeek-R1 challenges OpenAI’s o1 on cost and efficiency.
For builders, the signal is clear: the era of the 'loose loop' is ending. Whether it is through HITL checkpoints in LangGraph or the 78% success rates of specialized web automation libraries like browser-use, the focus has shifted toward deterministic outcomes and edge-ready reasoning. This issue breaks down the tools and protocols turning agentic theory into production reality.
Anthropic's MCP Solidifies as the 'USB-C' for Enterprise AI
Anthropic’s Model Context Protocol (MCP) has transitioned from a promising experiment to the defining standard for connecting AI agents to enterprise data. Often described as the 'USB-C for AI,' the protocol effectively solves the 'n+1' integration problem by decoupling tool logic from model-specific APIs. Recent 2026 adoption statistics show a significant surge in verified server counts and GitHub ecosystem signals, as major AI infrastructure companies increasingly align behind the protocol to facilitate secure, two-way connections between proprietary data and agentic tools.
The ecosystem's expansion is anchored by the MCP Registry, which now enables dynamic discovery of specialized servers for everything from Postgres databases to complex cloud-native environments. For developers, this shift toward standardization is more than just theoretical; it has already delivered a reported 40% reduction in boilerplate code. This allows engineering teams to pivot their focus away from manual connector maintenance and toward the core logic of agent reasoning, according to reports from Deepak Gupta and Digital Applied.
LangGraph Hardens Production Agents with State-Machine Persistence
LangGraph is redefining 'agentic engineering' by shifting the paradigm from conversational chatbots to robust, state-machine architectures. Unlike linear chains, the framework treats persistence as a primary feature, automatically saving checkpoints after every node completion to ensure agents survive restarts and manage long-running tasks. This deterministic approach is gaining massive traction, with 75% of enterprise pilots now prioritizing graph-based orchestration over simple sequences to maintain coordination and shared memory. By supporting 'human-in-the-loop' (HITL) checkpoints and 'interrupt and resume' capabilities, developers can now insert manual approval steps into agentic loops, providing the engineering rigor necessary for high-stakes deployments in financial or code-related environments.
Evaluating o1 and the Rise of Open-Weights Reasoning
OpenAI's o1 model has fundamentally altered agentic planning by integrating chain-of-thought reasoning directly into the inference loop, achieving an 83.3% on the AIME 2024 math competition. However, the high latency and cost of o1 have paved the way for DeepSeek-R1, which reportedly matches o1's performance across key reasoning benchmarks while being 27x cheaper to operate. To balance performance and production economics, developers are increasingly adopting 'hybrid planning' architectures where a high-reasoning model generates the initial multi-step execution graph, while high-throughput models handle the low-latency execution of individual tool calls.
Browser-use Scales Web Automation with 78% Success Rate
The browser-use library has emerged as a dominant orchestration layer for web-interacting agents, achieving a 78% success rate on difficult browser tasks. By providing a high-level wrapper around Playwright, the library allows agents to 'see' the DOM and perform actions like clicking and typing with minimal configuration, bypassing the limitations of raw HTML scraping through multi-modal reasoning. The ecosystem has expanded to include stealth cloud browsers and residential proxy networks spanning 195+ countries, ensuring that production-grade agents can mitigate anti-bot detection while performing tasks ranging from competitive intelligence to complex travel bookings.
OpenAI Swarm and Decentralized Handoffs
OpenAI's 'Swarm' framework is shifting multi-agent discourse toward a minimalist 'routines and handoffs' pattern that reduces the coordination overhead often leading to cascading failures in centralized systems.
Small Language Models Optimized for Agentic Tool Use
Small Language Models like Llama 3.2 3B and Phi-4 Mini are achieving near-frontier performance on function-calling tasks, with Llama 3.2 setting an 88.23% accuracy bar for mobile-ready agentic loops.
HuggingFace Highlights
From universal data interfaces to edge-based reasoning, the infrastructure for autonomous systems is maturing.
We have moved past the 'vibe check' era of agent development. Today’s landscape is defined by a push toward standardization and production-grade reliability. The Model Context Protocol (MCP) is emerging as the 'USB-C' of the agentic web, finally offering a way to swap data sources without rebuilding the stack from scratch. This isn't just about convenience; it is about lowering the 'abstraction tax' that has long plagued agent orchestration.
At the same time, we're seeing a bifurcation in how agents interact with the world. On one hand, Anthropic and OpenAI are pushing 'Computer Use' and 'Operator' patterns to bridge the legacy API gap through pixel-based reasoning. On the other, frameworks like PydanticAI are rebelling against heavy-handed state machines in favor of type-safe, developer-first patterns. Whether it is running 14B parameter reasoning models like Phi-4 at the edge or implementing graph-based persistent memory layers to solve the 'lost in the middle' problem, the focus has shifted to the last mile of engineering. This issue explores the tools and benchmarks—like WebArena-x—that are moving us closer to the 60% success threshold in complex, long-horizon tasks.
The 'USB-C for AI': MCP Standardizes the Enterprise Agentic Stack
The Model Context Protocol (MCP) has solidified its role as the 'USB-C port for AI,' providing a universal interface that allows LLM applications to swap data sources and tools without the need for bespoke, brittle integrations Synvestable. This standardization is driving a surge in specialized implementations, with top-tier MCP servers now available for major enterprise databases including PostgreSQL, MongoDB, and SQLite, as well as unstructured file systems Fastio. For practitioners, this eliminates the 'abstraction tax' of traditional frameworks; as previously noted, the smolagents library can now implement functional MCP-powered agents in as few as 50 lines of code.
The ecosystem is now pivoting from local experimentation to production-grade deployment, focusing on the critical 'last mile' of security and governance. Enterprise adoption guides emphasize that while a local server is easy to spin up, production environments require robust authentication, access control, and logging across dozens of concurrent MCP instances to remain viable Prefect. This shift is particularly vital for organizations connecting agents to secure, local data silos, where MCP acts as a governed gateway. Recent academic surveys also position MCP alongside emerging standards like the Agent Communication Protocol (ACP), marking a broader industry movement toward full agent-to-agent interoperability arXiv.
Computer Use APIs and 'Operator' Patterns Bridge the Legacy API Gap
The agentic web is pivoting from structured API calls to direct UI manipulation, led by Anthropic's 'Computer Use' and OpenAI's 'Operator'. This shift directly addresses the 'API gap' where legacy systems lack programmatic interfaces, allowing agents to navigate interfaces via pixel-based reasoning or DOM interaction. While developers report 85% success rates on isolated navigation tasks, real-world deployment reveals a 'performance cliff'; diagnostic data from the VAKRA benchmark indicates that even frontier models average 5.3 failure modes per trace in long-horizon browser tasks, highlighting that the move from 'demo' to 'production' requires more robust error-recovery loops.
PydanticAI: The Type-Safe Rebellion Against Heavy Orchestration
PydanticAI has emerged as a major contender in the orchestration space, prioritizing type safety and validation by leveraging the core Pydantic library. Unlike the explicit state-machine architecture of LangGraph, pydantic treats agents as high-level constructs defined by data schemas, resulting in a 30% reduction in boilerplate code for tool-calling tasks. While production audits from Alice Labs rank LangGraph as the primary choice for complex stateful workflows, PydanticAI is increasingly favored for its 'developer-first' experience and seamless integration into standard Python backends.
Beyond RAG: Persistent Graph-Based Memory Layers for Agent Autonomy
Agentic architectures are evolving from passive Retrieval-Augmented Generation (RAG) to active, persistent memory layers that synthesize knowledge across disconnected sessions. Systems like Mem0 utilize a hybrid of vector databases and graph-based storage to maintain a dynamic 'memory fabric,' achieving 95% precision in retrieving relevant context according to mem0/memory-demo. This hierarchy reduces hallucination rates by 25% in long-horizon tasks, effectively bypassing the 'lost in the middle' phenomenon often encountered in large context windows.
Phi-4: Scaling Reasoning Performance to the Edge
Microsoft's phi-4 brings 14B parameter reasoning to the edge, hitting 91.2% on the GSM8K benchmark for local agentic loops.
WebArena-x and the Multimodal Frontier
WebArena-x advances agent evaluation, showing industry success rates jumping from 14% to nearly 60% in multimodal environments.