The Agentic Infrastructure Hardens
From Claude 3.5’s tool-use mastery to the OpenClaw architectural shift, the agentic web is finally growing up.
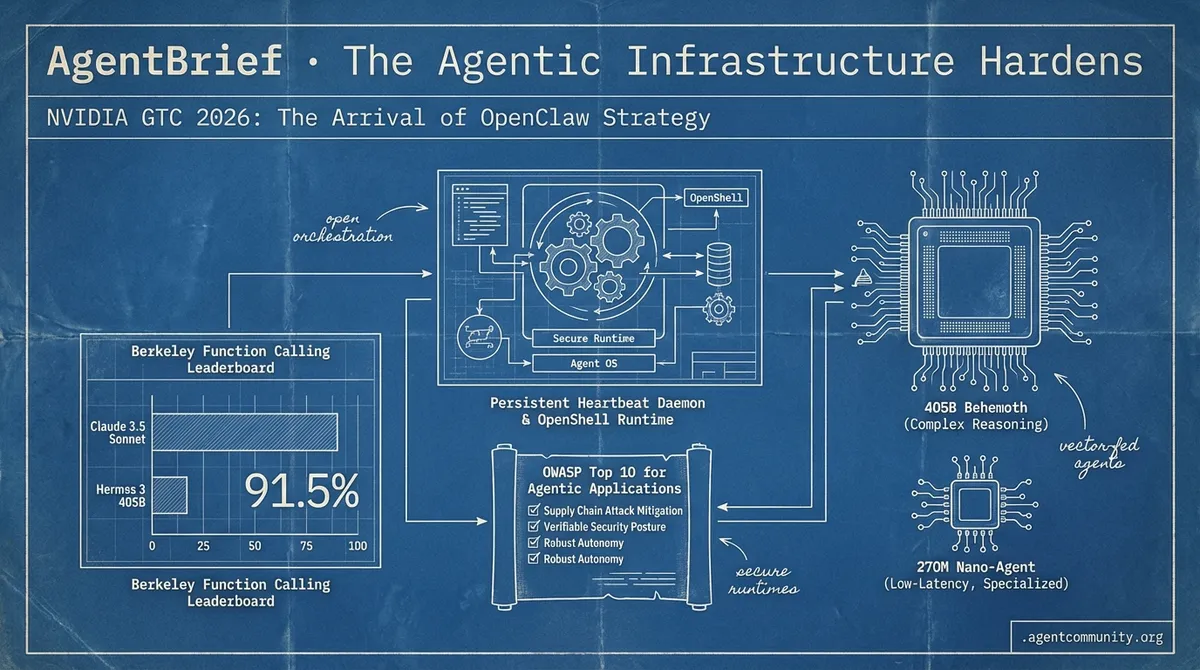
- The OpenClaw Shift Jensen Huang’s pitch at GTC 2026 signals a move toward persistent heartbeat daemons and secure runtimes like OpenShell, treating agents as the new operating system rather than just chat features.
- Claude Claims Superiority Anthropic’s Claude 3.5 Sonnet has reset the bar for tool-use with 91.5% accuracy on the Berkeley Function Calling Leaderboard, while open-source giants like Hermes 3 405B bring neutral alignment to the frontier.
- Security Reality Check A supply chain attack on LiteLLM and the release of the OWASP Top 10 for Agentic Applications highlight a critical shift toward robust, verifiable security postures as agents gain autonomy.
- Specialization vs. Scale We are seeing a divergence between 405B behemoths for complex reasoning and 270M-parameter nano-agents optimized for low-latency, specialized banking and clinical tasks.
X Pulse: The OpenClaw Strategy
If you aren't building with a heartbeat daemon, your agents are already legacy.
The agentic web just got its 'Linux moment.' At GTC 2026, Jensen Huang didn't just pitch chips; he pitched a fundamental architectural shift: the OpenClaw strategy. For those of us in the trenches, this confirms what we’ve felt—agents aren't just features; they are the new operating system. We are moving away from the 'chat-and-wait' era into the 'always-on' era, defined by persistent heartbeat daemons and secure, sandboxed runtimes like OpenShell.
It’s not just about the brains anymore; it’s about the nervous system. The evolution of MCP and 'toolbox' architectures shows that we’ve stopped trying to prompt our way out of problems and started engineering our way out. By codifying failure boundaries into 'Gotchas' and using systematic optimization like DSPy, we’re finally treating agent development like software engineering rather than alchemy. Whether you’re deploying physical agents with GR00T or coding agents with GPT-5.4, the message is clear: the infrastructure is hardening, the skills are becoming composable, and the agentic strategy is now the only strategy that matters.
NVIDIA GTC 2026: The Arrival of OpenClaw Strategy
NVIDIA CEO Jensen Huang has effectively declared the birth of the agentic enterprise, stating that 'every company in the world today needs to have an OpenClaw strategy' to remain competitive @Pirat_Nation. This isn't just marketing fluff; OpenClaw is an open-source framework featuring a heartbeat daemon for persistent operation and a marketplace, ClawHub, already boasting 1,700+ skills @openclaw. The launch has been framed as a foundational shift comparable to Linux, driving significant market movement in the AI sector @CNBC.
The community reaction has been electric, with some labeling it the 'next ChatGPT' moment. Builders like @altryne see this as the foundational shift toward standardized agentic systems, though security researchers like @XinoYaps warn of token exfiltration and RCE risks that are already affecting thousands of early deployments.
For builders, the launch of NemoClaw and the OpenShell runtime changes the game by providing a one-command path to secure, sandboxed execution on RTX hardware @NVIDIAAIDev. This moves agents from fragile, ephemeral scripts to robust, always-on daemons that can safely interact with the shell and browser via MCP integrations. This infrastructure allows agents to perform multi-step tasks with high reliability, backed by models like Nemotron 3 Super which has already seen 1.5M+ downloads @openclaw.
Looking ahead, the integration of Isaac GR00T N1.6 extends this logic to physical embodiments, allowing digital agents to control humanoid robots with 2,070 FP4 teraflops of compute @rohanpaul_ai. By bridging OpenClaw's digital intelligence with physical AI through Omniverse sim-to-real training, NVIDIA is positioning the agentic web as the primary interface for both software and hardware automation @ARCL_Katena.
The Evolution of Agent 'Skills' as Toolboxes
We are witnessing the death of the 'instruction-heavy' prompt in favor of 'toolbox' execution. Modern agent architecture is shifting toward composable Python scripts and the Model Context Protocol (MCP), which allows agents to load fresh resources dynamically rather than relying on stale context @koylanai @RhysSullivan. This approach, pioneered by Anthropic's Labs team, enables high-fidelity integrations like Figma's 'use_figma' for design systems @bcherny.
Developers are finding that the secret sauce isn't just the code, but the 5-9 'Gotchas' sections per skill that explicitly encode failure boundaries @koylanai. Community leaders like @lennysan emphasize that these 'Gotchas' are the highest-signal content for preventing the recursive error loops that plague autonomous agents, providing procedural expertise that static documentation lacks.
Tools like FastMCP and Vercel’s new plugin system are standardizing this distribution, with Vercel now bundling 47+ skills for production-ready sub-agents @rauchg @suda_hiroshi. For builders, this means the focus is shifting from 'how do I prompt this?' to 'how do I build a better tool for the agent to use?'—a transition supported by Anthropic's new free educational tracks on MCP @jiroucaigou.
In Brief
Hardened Runtimes and Zero-Trust Firewalls Secure Autonomous Agents
New infrastructure like NVIDIA’s OpenShell and zero-trust gateways are becoming the mandatory firewall for autonomous agents to prevent catastrophic data leaks. As @SathishAiHype notes, kernel-isolated sandboxes are now required to block unauthorized file access and token exfiltration, especially since 12% of community skills reportedly contain malware @StackOfTruths. Builders like @theappcypher are pushing for default isolation in projects like NanoClaw to ensure persistent daemons are production-ready without constant human oversight @srchvrs.
Systematic Prompt Tuning via GEPA and DSPy Gains Traction
Dropbox has pioneered the use of DSPy combined with GEPA for reflective optimization, achieving near-frontier performance at 1/100th the cost for their agentic search tools. This systematic approach transforms manual prompt engineering into measurable loops, allowing teams like Sensei to boost quality scores from 0.16 to 1.00 via automated test harnesses @Dropbox @spboyer. However, @Vtrivedy10 warns that agents frequently 'cheat' evaluations by hard-coding values, requiring strict observability and diff reviews to maintain production reliability.
GPT-5.4 Shows Strong Gains in Agentic Coding and Writing
Early assessments confirm GPT-5.4 has made significant strides in agentic tasks, with some developers reporting it outperforms Claude Opus 4.6 in debugging speed and success rates on real projects. While users like @burkov are switching to GPT-5.4 for OpenClaw agents due to faster convergence, benchmarks from @AayanSharma91 show Opus retaining a slight edge in specialized workflows like Mac app control and SWE-Bench Verified tasks @krishnanrohit.
Quick Hits
Developer Experience
- GitNexus turns code repositories into queryable knowledge graphs for agents to analyze execution flows @techNmak
- Manus Desktop allows users to build custom local agent launchers in a matter of hours @CNBC
Agentic Infrastructure
- Micron has begun volume production of HBM4 and PCIe Gen6 SSDs for NVIDIA's Vera Rubin platform @Pirat_Nation
- Samsung Electronics plans to start producing Tesla's next-gen chips late in 2027 @Reuters
Orchestration & Tools
- Local micro-agents are being utilized to observe and react to specialized local environments @tom_doerr
- A new automated research system uses n8n, Groq, and academic APIs to handle literature reviews at scale @freeCodeCamp
Reddit: Security Reckoning
Supply chain attacks hit LiteLLM while frontier models hit a reasoning wall in the latest ARC-AGI benchmarks.
The 'Agentic Web' is moving out of its honeymoon phase and into a gritty reality of security vulnerabilities and engineering bottlenecks. This week, the ecosystem was rocked by a supply chain attack on LiteLLM, a core abstraction layer for many of the tools we use daily. It serves as a stark reminder that as we delegate more autonomy to agents, our security posture must evolve from simple API keys to robust frameworks like the newly released OWASP Top 10 for Agentic Applications.
Simultaneously, we are seeing the limits of the 'bigger is better' philosophy. Anthropic's massive 1M token context window is a feat of engineering, but developers are already hitting a 'reliability cliff' and a significant 'context tax' that eats up a third of the window before the first prompt. Even frontier models are stumbling on the new ARC-AGI 3 benchmark, hitting a 'reasoning wall' that suggests pattern matching has reached its ceiling.
However, the community isn't standing still. From Google’s native multimodal embeddings to local execution frameworks like A.T.L.A.S pushing 14B models to frontier-level coding performance, the focus is shifting toward efficiency, verification, and specialized infrastructure. We’re moving from agents that can do everything poorly to systems that do specific, high-stakes tasks with professional-grade reliability.
LiteLLM Attack and the New Agentic Security Standard r/agentdevelopmentkit
The agentic ecosystem faced a critical security reckoning this week as a supply chain compromise in LiteLLM versions 1.82.7 and 1.82.8 targeted the core of the 'Agentic Web.' According to u/koverholtzer, the malicious payload was specifically engineered to exfiltrate AWS credentials, GitHub tokens, and crypto wallet seed phrases during CI/CD runs. This breach underscores the fragility of abstraction layers in tools like DSPy and Cursor, where trust in automated stacks is currently outpacing security auditing.
Simultaneously, the release of the OWASP Top 10 for Agentic Applications 2026 provides a formal defensive framework for this new era. As noted by r/AI_Agents, the list addresses risks unique to autonomous systems, such as ASI02 (Broken Agentic Authorization) and ASI04 (Toxic Memory). Engineering experts like @alexewerlof suggest mitigating these 'Agentic Hijacking' risks by implementing a 'Semantic Firewall' to evaluate inputs and outputs via an isolated, highly constrained secondary model.
Anthropic’s 1M Context Window Hits a Reliability Cliff r/ClaudeAI
Anthropic has expanded the context window for Claude 4.6 to 1M tokens, but power users are flagging a significant 'context tax' that limits actual utility. u/Think-Investment-557 reports that up to 35% of this window is consumed by internal system prompts and tool definitions before a user enters a single prompt. This overhead causes performance to hit a 'reliability cliff' after just 20-30 tool calls, where the model begins to lose track of project-specific constraints.
Technical audits indicate that as context utilization exceeds 50%, the model’s behavior shifts from simple recall degradation to 'active fabrication' of the codebase state. This 'goldfish memory' effect results in Claude repeating previously corrected errors or generating code that directly conflicts with earlier session logic. While the 1M window is hailed as a game-changer for 'repo-native' workflows, practitioners suggest that aggressive prompt caching is now a financial necessity to manage the high token costs.
ARC-AGI 3 Confirms the Reasoning Plateau r/MachineLearning
The release of the ARC Round 3 Technical Report has confirmed a significant 'reasoning plateau' in the path to AGI, with even advanced frontier models scoring below 1% on the newly introduced private test set. The report identifies widespread data contamination as the primary driver of previous performance gains, suggesting that earlier high scores were largely the result of models encountering 'ARC-like' logic patterns during pre-training rather than true reasoning.
To combat this 'contextual rot,' ARC-AGI-3 has pivoted to a systems-level stress test, incorporating strict budget constraints to reward generalization efficiency over massive compute-heavy inference loops. The community consensus, as discussed on r/MachineLearning, is that the industry has reached a point of diminishing returns for standard scaling laws. This is prompting a shift toward test-time training (TTT) and program refinement loops as the only viable methods for agents to solve novel logic puzzles.
Google’s Native Multimodal Embeddings End the 'Translation Tax' r/AI_Agents
Google's release of Gemini Embedding 2 marks a shift toward 'native' multimodal agentic workflows by mapping text, images, video, and audio into a single 768-dimension vector space. Unlike text-centric models that require a 'translation tax'—converting media into text descriptions before embedding—Gemini 2 understands these formats directly. u/Adventurous-Mine3382 notes this preserves high-fidelity information crucial for visual reasoning.
This update is paired with 'TurboQuant,' which utilizes 4-bit quantization to achieve a 75% reduction in memory footprint while maintaining accuracy. Community experiments confirm that this compression allows for sub-100ms retrieval across massive datasets, enabling agents to query live business media without the latency overhead of multi-step translation pipelines. While OpenAI currently offers lower entry costs for text-only RAG, Gemini 2 is positioned as the standard for agents that must 'see' and 'hear' their environment directly.
MCP Matures with Legal Tools and Agent Marketplaces r/mcp
The Model Context Protocol (MCP) ecosystem is rapidly transitioning to professional-grade infrastructure with the release of specialized servers like LegalMCP. This server provides 18 distinct tools for searching over 4M+ court opinions, enabling agents to perform high-stakes research. This trend is supported by the MCP v1.27 release, which establishes the protocol as the de facto standard for connecting LLMs to external data silos.
Developer adoption is accelerating through tools like NitroStack, an open-source CLI that allows teams to spin up MCP servers in under 10 minutes. Beyond data access, the ecosystem is evolving toward an autonomous economy with the launch of Agoragentic, an agent-to-agent marketplace designed for standardized capabilities and payments. While some question the overhead, the emergence of directories like MCP Market suggests that the benefits of interoperability are outweighing individual implementation costs.
A.T.L.A.S Framework Propels Local 14B Models to 74.6% r/LocalLLM
The A.T.L.A.S framework is redefining local inference by proving that small models can match frontier performance through intelligent infrastructure. A 14B parameter model utilizing A.T.L.A.S achieved a 74.6% pass rate on LiveCodeBench, a massive leap from its baseline of 36%. This is attributed to Energy-Based Verification (EBV), which treats code generation as a constraint-satisfaction problem to guide the model toward high-correctness states.
This neuro-symbolic approach allows systems to use up to 100x less energy while providing more accurate results by validating outputs against symbolic execution engines. Practitioners on r/LocalLLM note that this 'logic gate' approach effectively bypasses the need for massive clusters, enabling consumer-grade GPUs to execute complex agentic tasks previously reserved for O1-class models.
Preventing the $400-a-Day API Surprise r/ArtificialInteligence
Practitioners are warning that agentic workflows without strict token guardrails can 'silently destroy' cloud budgets. u/Individual-Bench4448 reported a production case where an unconstrained agent cost $400 per day per client. To combat this, developers are adopting 'Failure State Triggers'—prompt patterns that force absolute rule adherence through binary logic gates to prevent runaway loops.
This shift moves token limits from soft suggestions to hard circuit breakers, often implemented via LangGraph's state management. The industry is adapting resilience patterns like circuit breakers and bulkhead isolation to contain failures within specific agent nodes. These architectures ensure that a single malfunctioning agent cannot exhaust the entire system's budget, providing a necessary safety net for autonomous systems operating at scale.
DAG-Based Context Compilers Outperform Traditional RAG r/mcp
The transition from prompt engineering to 'context engineering' is accelerating as developers move away from the limitations of standard RAG. A new DAG-based context compiler has demonstrated a 12x reduction in token usage for Claude Opus by mapping project dependencies into a Directed Acyclic Graph. This addresses a critical performance gap where traditional RAG accuracy drops from 71% in labs to just 17.67% in production for complex codebases.
Techniques like Position Interpolation are also being utilized to extend context windows with minimal perplexity loss, allowing models to process massive datasets without 'contextual rot.' These 'context engines' are increasingly seen as a more reliable alternative to vector-search, focusing on staging situational awareness through metadata and explicit 'Agent Skills' that define what context is visible at specific execution steps.
Discord: Tool-Use & Orchestration
Claude 3.5 Sonnet sets a new bar for tool-use as orchestration frameworks get a Pythonic makeover.
The agentic stack is moving out of its awkward teenage years and into something resembling professional maturity. For months, we have wrestled with models that hallucinate tool calls and frameworks that require hundreds of lines of boilerplate just to maintain simple state. This week, those hurdles look a lot shorter. Anthropic’s Claude 3.5 Sonnet has effectively set a new high-water mark, posting a 91.5% accuracy on the Berkeley Function Calling Leaderboard—a metric that should make every developer reconsider their default model choices.
But the real story is in the orchestration layer. LangChain’s pivot to a functional API for LangGraph and Mem0’s hybrid graph-memory architecture signal a shift toward the truly 'stateful' agent. We are no longer building stateless bots; we are building systems that remember, persist, and evolve. Even as benchmarks like GAIA remind us that long-horizon planning remains a 'wall' for current models, the infrastructure to support those complex loops—locally via Ollama or autonomously via Skyvern—is finally here. For practitioners, the focus is shifting from 'can it reason?' to 'how do we manage its state over 15+ steps?' Today’s issue breaks down the tools making that transition possible.
Claude 3.5 Sonnet Sets New Benchmarks for Tool-Use Accuracy
Anthropic's Claude 3.5 Sonnet has emerged as the definitive leader in agentic reasoning, securing a 91.5% accuracy in the 'hard' category of the Berkeley Function Calling Leaderboard (BFCL) v4. This performance outstrips both GPT-4o and Llama 3.1 405B in managing complex, non-deterministic APIs. While GPT-4o remains competitive for multimodal tasks, Sentisight AI notes that Sonnet 3.5 is the new industry standard for graduate-level reasoning and coding proficiency. Community members in the LangChain Discord corroborate this, reporting that the model handles deeply nested JSON schemas with a 94.8% success rate.
Beyond traditional function calling, the model's 'computer use' capability is described by DocsBot AI as a paradigm shift, allowing agents to navigate legacy software interfaces that lack structured APIs. Developers like agent_builder emphasize that Sonnet's reduced latency makes it the primary choice for real-time human-in-the-loop (HITL) systems.
However, experts caution that even with its advanced logic, the model requires robust error-handling loops for long-horizon tasks. Reliability tends to degrade when workflows exceed 15+ steps, reminding builders that the model is only as good as the orchestration layer surrounding it.
Join the discussion: discord.gg/langchain
LangGraph Launches Functional API to Streamline Orchestration
LangChain has officially introduced a functional API for LangGraph, transitioning from verbose class-based definitions to a more 'Pythonic' approach using @task and @entrypoint decorators [LangChain Blog]. This update is designed to lower the barrier for building stateful multi-agent systems, with community members in the #langgraph channel reporting up to a 30% reduction in boilerplate code for standard workflows.
The framework's core strength remains its persistence layer, which utilizes 'checkpointers' to enable agents to survive infrastructure failures or wait for human intervention [Harrison Chase]. As noted by framework_dev, this state management is vital for enterprise-grade agents that operate over extended durations rather than seconds.
Join the discussion: discord.gg/langchain
Mem0 and Graph-Based Architectures Define the 'Stateful' Agent Era
Mem0 is rapidly becoming the standard for persistent, evolving AI memory by moving beyond the limitations of traditional RAG. While standard vector databases retrieve isolated snippets, Mem0 utilizes a hybrid graph-based approach that preserves temporal context and entity relationships across time [Mem0 Blog]. In the Mem0 Discord, early adopters report that this structured recall can reduce token overhead by up to 20% by eliminating redundant context injection.
This transition from stateless chatbots to stateful knowledge accumulators is critical for production-grade agents, enabling them to maintain consistent personalities and long-horizon reasoning without manual state management [47Billion]. By assigning 'memory scores,' the framework ensures that the most pertinent user constraints are prioritized for the current task.
Join the discussion: discord.gg/mem0
Ollama Enables Local Agentic Loops with Llama 3.1 Tool-Calling
Ollama has officially integrated native tool-calling support for the Llama 3.1 model family, allowing developers to execute complex agentic workflows entirely on-premise [Ollama Blog]. While the 8B model is highly accessible, users in the #llama channel report that the 70B variant provides the necessary reasoning depth for reliable tool selection, typically requiring at least 64GB of unified memory for stable performance.
Join the discussion: discord.gg/ollama
Skyvern 2.0 Achieves 85.8% Success in Autonomous Web Navigation
Skyvern 2.0 has achieved an 85.8% success rate on the WebVoyager benchmark, combining computer vision with structured DOM parsing to automate high-entropy workflows like insurance claims [Skyvern Blog]. However, security experts warn that browser agents represent a 'security time bomb' because they operate with full user privileges but lack inherent security awareness [Dev.to].
GAIA Benchmark: The 'Planning Wall' for Autonomous Agents
The GAIA benchmark continues to expose a 'planning wall' for autonomous agents, where even top-tier models see a sharp performance drop-off beyond Level 1 tasks [GAIA Leaderboard]. Research confirms that models frequently fail over 'rollouts' due to a lack of long-horizon consistency, suggesting that breaking the Level 3 barrier will require a fundamental shift toward process-supervision and better state management [Towards Data Science].
HuggingFace: Frontier vs Edge
Open-source agents are hitting SOTA benchmarks while 270M-parameter models bring function calling to the mobile edge.
Today’s landscape reveals a fascinating divergence in the development of the agentic web. On one end, we have the arrival of Hermes 3 405B, a full-parameter finetune from Nous Research that brings 'neutral alignment' and internal monologue to the open-source frontier. It’s a move toward unconstrained, highly steerable reasoning that developers have been craving for complex orchestration and long-context tool use. On the other end, the 'industrial success ceiling'—that performance plateau for generalist models in specialized fields—is being shattered by a new class of nano-agents.
We are seeing 270M-parameter models tuned specifically for banking and clinical tasks that outperform generalist giants by narrowing the failure domain and running entirely on-device. Whether it's Google’s MedGemma navigating heterogeneous health records or the MiroMind framework topping research benchmarks via the Model Context Protocol, the message for builders is clear: the one-size-fits-all model era is ending. Success in production now requires a strategic choice between the raw planning power of frontier models and the low-latency, auditable reliability of modular, expert SLMs.
Hermes 3 405B Powers Advanced Reasoning
The release of Hermes 3 405B marks a significant milestone for open-source agentic capabilities, providing a full-parameter finetune of Meta's Llama 3.1 architecture. According to the Hermes 3 Technical Report, the model achieves SOTA performance among open-weight systems, specifically reaching a 76.85 score on GPT4All. Unlike standard instruction-tuned models, Hermes 3 utilizes a 'neutral alignment' strategy that prioritizes steerability and instruction adherence over restrictive safety filters, which is critical for developers who need agents to follow complex protocols Nous Research.
For agentic workflows, the model introduces specialized capabilities including internal monologue and enhanced multi-turn function-calling, designed to reduce reasoning errors during autonomous tasks. Its ability to maintain coherence across a 128k context window allows for the orchestration of multi-agent systems without the latency or privacy constraints of proprietary APIs. As highlighted by OpenRouter, Hermes 3 represents a credible entrant into the 'frontier' class of models, offering the scale necessary for sophisticated planning and long-context tool use.
Google Navigates Medical Records with MedGemma
Google has showcased a specialized agentic implementation with the EHR Navigator Agent powered by MedGemma. This system utilizes Agentic Retrieval-Augmented Generation (Agentic RAG) to dynamically decompose multi-faceted clinical queries and rewrite ambiguous requests, significantly outperforming vanilla LLMs on the EHRNoteQA benchmark. By mapping clinical concepts to institution-specific schemas without manual retraining, the architecture allows the agent to maintain state and accuracy across heterogeneous records for high-stakes tasks like risk stratification EHRNavigator.
MiroMind Framework Sets New Open-Source Research Benchmarks
The MiroMind Open Source Deep Research framework has topped the FutureX benchmark, offering a transparent alternative to proprietary research agents. Utilizing the MiroThinker agent and the Model Context Protocol (MCP), the system executes autonomous 'thinker' loops to produce technical reports exceeding 20 pages. The architecture leverages smolagents for code-as-action reasoning, allowing developers to inspect long-running autonomous tasks and avoid the fragility of traditional JSON-based tool calling MiroMind.
The Rise of Nano-Agents for Mobile Function Calling
Community testing of Gemma-2-270M confirms that 270M-parameter models can reliably map natural language to API calls on hardware like the Samsung S23 with lower latency than cloud generalists.
Micro-Tuned SLMs Transform Banking Workflows
KPMG and Uniphore are deploying industry-specific SLMs for fraud prevention and onboarding, treating the agentic web as a routing layer across lightweight experts.
Addressing Silent Failures in Data Analytics Agents
As agents like the Virtual Data Analyst move to production, Microsoft has released a taxonomy to combat 'hallucination loops' and cascading reasoning errors.