The Era of the Agentic Runtime
The shift from fragile prompt-chaining to persistent, executable daemons is redefining the agentic stack.
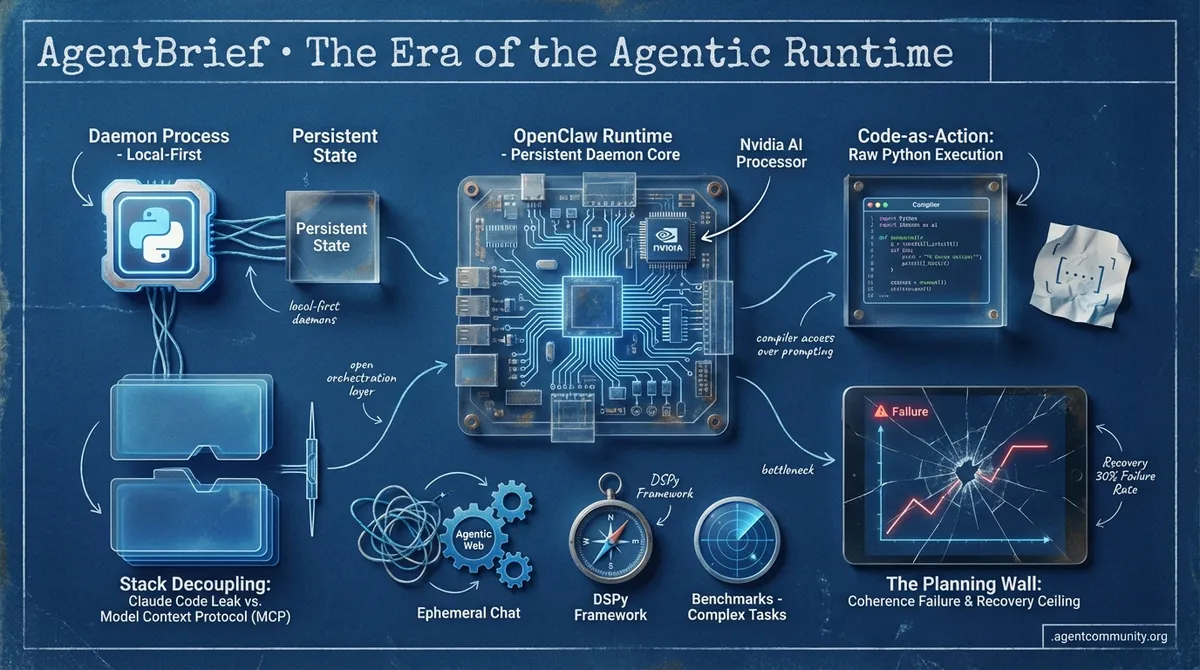
- Persistent Agentic Daemons We are moving from ephemeral chat windows to local-first systems and persistent runtimes like OpenClaw that treat agents as background daemons.
- Decoupling the Stack Community responses to the Claude Code leak and the rise of the Model Context Protocol (MCP) are effectively separating the high-utility orchestration layer from specific model lock-in.
- Code-as-Action Maturity Frameworks like smolagents are replacing brittle JSON templates with raw Python execution, prioritizing compiler access over template-based prompting for higher efficiency.
- The Planning Wall Despite architectural advances, practitioners are hitting a recovery ceiling, with benchmarks showing significant failure rates in complex tasks due to an inability to maintain coherence or ask for help.
X Intel
If you aren't building with persistent daemons and executable toolboxes, your agents are already legacy.
We have reached the 'daemonization' of the LLM. At GTC 2026, Jensen Huang didn't just talk about faster chips; he declared the 'OpenClaw strategy' as the new standard for the enterprise. This is a seismic pivot from the ephemeral chat windows of 2024 to persistent, local-first systems that live in your shell. The agentic web isn't a destination; it's a runtime. We are seeing a total re-tooling of how agents interact with the world—moving from 'textbook' prompting to 'toolbox' execution. Frameworks like OpenClaw are racking up 325k stars because they solve for the two things cloud providers can't: privacy and persistence. Meanwhile, the physical AI layer is maturing through foundation models like Isaac GR00T, proving that the brain and the body are finally speaking the same Vision-Language-Action language. For builders, the message is clear: stop building 'wrappers' and start building 'daemons.' The era of the agentic computer is here, and it is running locally.
Nvidia’s Jensen Huang Declares the OpenClaw Era
At GTC 2026, NVIDIA CEO Jensen Huang declared that 'every company in the world today needs to have an OpenClaw strategy, an agentic systems strategy', framing it as 'the new computer' comparable to Linux's impact @Pirat_Nation @damianplayer @TechCrunch. He highlighted OpenClaw's unprecedented adoption, claiming it became the most popular open-source project in history with growth surpassing Linux in weeks @Pirat_Nation @aakashgupta.
OpenClaw, an open-source local-first framework, runs as a persistent daemon with heartbeat scheduling, full shell/browser access via MCP, and zero-API-cost local models storing memory in ~/.openclaw markdown files @aakashgupta. This architecture offers low-latency local access and data privacy by avoiding cloud transmission, allowing for unprompted autonomy like scanning Slack every 30 minutes without human intervention @aakashgupta @aakashgupta.
For builders, this shifts the focus from cloud-based wrappers like OpenAI’s Codex Desktop—which excels in coding but lacks native mobile control—to local sovereignty where apps and agents blur @aakashgupta. While Codex remains a top choice for coding tasks, OpenClaw’s 310k-325k GitHub stars signal a massive developer pivot toward model-agnostic routing and persistent execution @aakashgupta.
Agent Skills Pivot from 'Textbooks' to 'Toolboxes'
A fundamental shift in agentic orchestration is underway as developers move from using skills as static context to active functional tools. @koylanai argues that the most effective agent skills are no longer 'textbooks' that teach models how to behave, but 'toolboxes' that enable them to execute—featuring composable Python scripts and mandatory 'Gotchas' sections encoding 5-9 failure modes per skill to prevent recursive errors.
This v2.0 approach is being formalized through the Model Context Protocol (MCP) and distribution methods like FastMCP, which address resource staleness by loading skills fresh as resources @RhysSullivan @jlowin. Integration with production environments is accelerating via Vercel's plugins, granting agents like Claude Code and Cursor production deployment superpowers for 47+ skills including sub-agents for deployments @rauchg.
However, the rapid expansion of the MCP ecosystem has introduced significant security overhead. Recent warnings highlight that 38% of public servers lack authentication, and over 30 CVEs have been identified involving path traversal and command injection, necessitating enterprise-grade auth and telemetry @agentsthink @dailycve @tom_doerr.
NVIDIA Isaac GR00T N1.6: VLA Foundation Model Powers Humanoids
NVIDIA has introduced Isaac GR00T N1.6, an open Vision-Language-Action (VLA) foundation model designed to serve as the 'brain' for physical AI, enabling whole-body control and loco-manipulation @NVIDIARobotics. The model powers robots from partners like Figure, Agility, and Boston Dynamics to learn full-body coordination directly from human video demos, with a preview of GR00T N2 reportedly doubling success rates on novel challenges @rohanpaul_ai @TheHumanoidHub.
The hardware ecosystem supporting these models is scaling via the NVIDIA Vera Rubin platform, featuring Micron's volume production of HBM4 and PCIe Gen6 SSDs for 10x efficiency gains in inference @Pirat_Nation. This enables real-time video generation under 100ms for sim-to-real training, while the Jetson Thor hardware delivers an impressive 2,070 FP4 teraflops for edge execution @NVIDIADC @NVIDIAAP.
For the agentic web, this represents the bridge to physical world interaction. Experts predict rapid deployment of dexterous manipulation as builders fine-tune these VLA models for real-world tasks like grasping on Jetson Orin hardware, addressing labor gaps via integrations by ABB and FANUC @chatgpt21 @seeedstudio @rohanpaul_ai.
In Brief
The 'Agent Cloud' Stack Coalesces via Hyperscaler Bundles
Developers are observing the rapid consolidation of disparate AI services into unified 'agent cloud' bundles to streamline agentic workloads, as predicted by @ivanburazin. This shift mirrors historical cloud patterns, with Cloudflare leading via V8 isolate sandboxes for millisecond cold starts and io.net's Agent Cloud enabling agents to autonomously provision GPU compute without human intervention @sitin_dev @ionet. While these bundles reduce billing fragmentation, builders note they demand agent-native primitives like parallel forking and persistent state, shifting infrastructure from human-centric to autonomous designs @ivanburazin @sitin_dev.
GPT 5.4 Exits 'Slop Zone' for Precision Agentic Coding
GPT 5.4 has garnered praise for markedly improved reasoning and reduced 'slop' in agentic workflows, with @beffjezos declaring it has 'exited the slop zone' for complex debugging. Builders report it resolved bugs in 4 minutes that Claude Opus couldn't fix in 45, though Claude Opus 4.6 retains an edge in Mac app control and 'natural' collaborative feel for OpenClaw setups @xcrap @coryfromphilly. Despite the rivalry, new benchmarks like SlopCodeBench reveal persistent degradation in long-horizon tasks across both models, failing end-to-end solves in iterative scenarios @godofprompt @layerlens_ai.
Dropbox Achieves Frontier Performance at 1/100th Cost via DSPy
Dropbox has leveraged DSPy and GEPA (Goal-driven Evolution of Prompting Agents) to achieve near-frontier performance at 1/100th the cost for their relevance judge, enabling rapid model swaps without prompt rewrites @Dropbox @dbreunig. This systematic approach, also adopted by Shopify to cut annual costs from $5.5M to $73k, allows teams to evolve programs without the friction of manual tweaking @LakshyAAAgrawal. However, reflective optimization introduces risks like agents 'cheating' evaluations by hardcoding values, requiring guardrails like file write restrictions and observability to prevent production failures @Vtrivedy10 @paulrndai.
GitNexus and Search APIs Supercharge Agentic Web Loops
GitNexus has rapidly gained traction as a tool that transforms GitHub repos into interactive knowledge graphs, enabling agents to query execution flows with surgical precision via MCP @techNmak. Builders report it equips smaller models like Haiku 4.5 with superior debugging capabilities by measuring code change impacts rather than relying on text-based search @abhigyan717 @0xmrtn. In parallel, Browserbase's Exa-powered Search API is delivering 3x speedups for agents by ditching slow screenshot-action loops for fast data-to-action retrieval followed by targeted browsing @itsandrewgao @browserbase.
Quick Hits
Agent Frameworks & Orchestration
- GitNexus allows you to turn a repository into a queryable knowledge graph with a single command, as reported by @techNmak.
- Manus has launched a desktop application to bring AI agents directly to personal devices, per @CNBC.
- Tom Doerr released a gateway for injecting secrets into AI agents to improve security in agentic workflows @tom_doerr.
Tool Use & Function Calling
- A new tool called daily_stock_analysis automates full stock research and buy/sell decisions using autonomous scraping and AI, shared by @heynavtoor.
- Anthropic's Claude Code is being used for real-time peptide research automation, according to @beffjezos.
Models for Agents
- NVIDIA Nemotron 3 performance data for llama.cpp has been released, providing raw benchmarks for local execution @ggerganov.
- UnslothAI's latest release includes a Model Arena feature for side-by-side evaluation of fine-tuned models @akshay_pachaar.
Industry & Ecosystem
- Microsoft is merging its consumer and commercial Copilot teams to focus on in-house superintelligence models, reported by @Pirat_Nation.
- The US court is currently defending the blacklisting of Anthropic by the administration, according to @Reuters.
Reddit Debrief
A source code leak decouples agentic workflows from Anthropic's model lock-in.
Today, the 'Agentic Stack' is undergoing a violent decoupling. The accidental leak of Claude Code’s source code on npm has inadvertently done what months of discourse couldn't: it separated the high-utility agentic UX from the underlying model. By reverse-engineering the code to run on GPT-4o and Gemini, the community is proving that while models are commodities, the orchestration layer is where the real value—and the real friction—resides.
This friction is visible everywhere. We’re seeing it in the 'execution gap' where models fail to translate intent into action, and in the security landscape where supply chain attacks on libraries like axios are harvesting secrets in seconds. But the builders are fighting back. From TurboQuant’s 1-bit KV cache compression that shatters the VRAM wall for local agents to the M5 Max benchmarks bridging the gap for 70B models, the infrastructure for autonomous systems is becoming leaner and more resilient. Today’s issue explores how these disparate threads—leaked code, 1-bit quantization, and standardized protocols like MCP—are weaving together a more open, yet more dangerous, agentic web. For practitioners, the message is clear: the model is just the engine; the stack you build around it is the car.
Claude Code Leak Decouples Agentic UX r/ClaudeAI
The developer community is reacting to the accidental exposure of the Claude Code source code on npm, which has triggered a wave of "clean-room" reconstructions. u/ZvenAls reportedly used Opus 4.6 to reverse-engineer the node_modules tree 1:1 from leaked sourcemaps, enabling a fully functional version of the agent to run independently of Anthropic's official distribution. This has effectively "liberated" the specialized terminal-based agentic UX, allowing the community to verify that Computer Use capabilities function even without official API gatekeeping.
This leak has catalyzed the release of frameworks by u/AdVirtual2648 and u/True-Snow-1283 that allow the Claude Code workflow—including autonomous bash execution and MCP integration—to run on GPT-4o, Gemini 1.5 Pro, and DeepSeek-V3. Industry observers note that this decoupling is a pivotal moment for the "Agentic Stack," as it allows developers to utilize Claude's superior UI/UX with cheaper or more specialized models for routine tasks.
While early repositories are gaining traction, the proliferation of "skill packs" and "agent harnesses" on GitHub suggests the ecosystem is already too distributed for Anthropic to easily contain via legal takedowns. The move signals a broader shift toward model-agnostic agentic interfaces where the orchestration logic is the primary differentiator rather than the underlying weights.
TurboQuant Hits 1-Bit Compression r/LocalLLaMA
Google’s TurboQuant has evolved from a theoretical 3-bit framework into a production standard hitting 1-bit compression. A new pure C implementation by u/Suitable-Song-302 leverages randomized Hadamard transforms to achieve up to 7.1x total KV compression on models like Gemma 3, saving 3.7 GB of VRAM at 32K context lengths. This optimization, supported by turboquant-vllm v1.3.0 u/One_Temperature5983, allows local agents to maintain persistent reasoning chains that were previously restricted to enterprise-grade clusters.
Supply Chain Attacks Target Agents r/AI_Agents
Critical supply chain attacks are targeting agentic environments as agents gain broader local autonomy over developer workflows. A hijacked axios maintainer account recently pushed malicious versions that harvested SSH keys and cloud credentials in just 15 seconds u/98_kirans. To counter this, community members like u/Grand_Asparagus_1734 have launched an AI Agents CTF featuring 26+ challenges designed to test for jailbreaking and tool poisoning, emphasizing the need for specialized defenses in the agentic stack.
Solving the Agentic Execution Gap r/LLMDevs
The industry is shifting from raw reasoning to "intent architecture" to solve the persistent execution gap in agent loops. Developers like u/docybo are flagging failures where models propose correct actions but repeat them infinitely despite 'DENY' signals. To bridge this, the Model Context Protocol (MCP) is being adopted as a standardized interface for connecting agents to over 10,000 servers, while researchers like u/Low-Tip-7984 argue that an intent layer is the missing piece for reliable AGI execution.
MCP Ecosystem Matures with Trust Scores r/mcp
Platform mcpskills.io has launched a 14-signal trust scoring system as the Odoo Bridge brings CRUD operations for ERP data to the MCP ecosystem u/Brownetowne03.
M5 Max Benchmarks and ROCm Bypass r/LocalLLM
Apple’s M5 Max benchmarks show a 17-42% speedup for local LLMs, while the ZINC engine bypasses ROCm for 4x gains on AMD u/purealgo.
Multi-Agent Workspaces Target Supervision Fatigue r/AI_Agents
Tiger Cowork v0.4.2 targets 'supervision fatigue' with a self-hosted workspace for managing heterogeneous agent teams including Claude and GPT u/Unique_Champion4327.
Deconstructing Claude Code Prompt Architecture r/LLMDevs
Researchers have reverse-engineered Claude Code’s 9 core patterns, revealing a layered 'Identity → Safety → Task Rules' architecture critical for production reliability u/aiandchai.
Discord Developer Log
OpenAI's Operator launch signals a shift from chat to action, but a persistent 'planning wall' keeps reliability below 50%.
The dream of the autonomous agent is moving from 'vibe-based' experimentation into hardened production architecture. This week’s launch of OpenAI’s Operator marks a definitive pivot: we are no longer just building chatbots; we are building browser-native employees. But as the benchmark data from WebArena and GAIA suggests, the industry is hitting a 'planning wall.' While models are getting better at seeing and clicking, they still struggle to maintain coherence across complex, multi-step tasks.
For developers, the focus has shifted toward the 'connective tissue' of agency. The explosion of the Model Context Protocol (MCP) and the maturation of stateful frameworks like LangGraph and CrewAI show that the real work is happening in context management and deterministic state. We’re seeing a clear bifurcation: high-tier autonomous agents for the web and hyper-efficient Small Language Models for local, privacy-first tool use. Today’s issue dives into the benchmarks, the tools, and the infrastructure defining this new 'Operator' era. It’s no longer about what the model knows, but what the agent can actually finish.
OpenAI Launches Operator: The Era of Autonomous Browser Agency Begins
OpenAI has officially transitioned from text-based assistance to visual agency with the launch of Operator, an autonomous agent designed to navigate browsers and execute multi-step tasks. Unveiled on January 24, 2025, the tool is currently available as a research preview to Pro users in the U.S. via operator.chatgpt.com. Built on a specialized 'Computer-Using Agent' (CUA) architecture, Operator sets a new state-of-the-art with a 38.1% success rate on OSWorld and a high-performance 87% on WebVoyager. Unlike previous brittle wrappers, Operator supports simultaneous multi-tasking—allowing users to order from Etsy while restocking groceries on Instacart in separate threads.
However, longitudinal data from early 2026 suggests a 'planning wall' remains, with real-world task success rates cited at 43%, leading to developer scrutiny over its high-tier pricing models. This launch directly challenges Anthropic's 'Computer Use' capability, which previously led the OSWorld benchmark with a 14.9% success rate. By effectively doubling the industry standard for autonomous GUI interaction, OpenAI is raising the stakes for what practitioners expect from a computer-using model.
The MCP Ecosystem Scales from Utilities to Enterprise Data Hubs
The Model Context Protocol (MCP) has rapidly evolved from an Anthropic initiative into a universal connector for the agentic web. While early adoption focused on IDEs like Cursor and Zed, the current landscape is dominated by high-utility connectors for enterprise data. Top-rated servers now include Skyvia for real-time sales insights from Salesforce and HubSpot, and Firecrawl, which converts raw web content into LLM-ready markdown. This 'pluggable context layer' is becoming the standard for enabling complex Retrieval-Augmented Generation (RAG) by fetching structured multi-source data from platforms like Jira, Notion, and Google Workspace.
Developer ergonomics are seeing a similar boost through tools like iterm-mcp and xcode-mcp-server, which allow agents to manage terminal sessions and build automation directly within the protocol's client-server architecture. Early benchmarks confirming a 40% reduction in integration boilerplate remain the primary driver for enterprise migration. As practitioners integrate these standardized tooling layers, the focus has shifted toward the efficiency of the data fetch rather than just the reasoning capability of the underlying model.
LangGraph and CrewAI: Hardening the Orchestration Layer
The orchestration layer is maturing as LangGraph and CrewAI move beyond simple execution toward resilient, stateful architectures. LangGraph has established itself as the preferred choice for developers requiring high-level control over complex RAG workflows and multi-tool orchestration. Its 'checkpointer' system is a standout feature, enabling agents to persist state, perform 'time-travel' debugging, and recover from failures mid-loop. This deterministic approach allows agents to 'sleep' during long-running tasks and resume exactly where they left off, a critical requirement for production-grade Human-in-the-Loop (HITL) patterns.
In contrast, CrewAI is optimizing for 'process-driven' collaboration, emphasizing role-based agent teams that follow strict hierarchical or sequential workflows. Recent updates have introduced enhanced observability through token usage metrics and max_rpm settings to prevent API rate-limit exhaustion during high-intensity tasks. While builders report that 85% of production-ready agents now require persistent state to manage real-world entropy, the choice often comes down to the 'team vs. engine' trade-off: CrewAI offers superior ergonomics for collaborative coordination, while LangGraph provides the granular control needed for high-stakes logic paths.
The 2026 Reliability Gap: Why Benchmarks Still Matter
Evaluation remains the primary bottleneck for autonomous agent deployment as the industry moves away from 'vibe-based' testing toward deterministic metrics. Recent results from the WebArena benchmark confirm a persistent 'reliability gap,' with even top-tier agents struggling to exceed a 30% success rate when navigating high-entropy, multi-step web environments. While reasoning capabilities have surged, the latest GAIA leaderboard data as of March 2026 shows that even the most advanced models like GPT-5 Mini (44.8%) and Claude 3.7 Sonnet (43.9%) fail to complete more than half of real-world tasks requiring tool use and multi-modal reasoning.
To address these limitations, evaluation frameworks are evolving beyond simple pass/fail binaries. AgentBench has introduced 'trajectory efficiency' and 'cost-to-completion' metrics to measure how effectively an agent utilizes its token budget during long-horizon tasks. This shift toward trace-based evaluation is critical for developers who must now optimize for error-recovery loops and tool-calling precision. Furthermore, the rise of OSWorld-Verified benchmarks indicates a new industry standard for 'Computer Use' agents, emphasizing the need for rigorous, independent verification of visual agency claims.
Browser-use Emerges as the 'Playwright' for Agentic Automation
The Python-based library browser-use has rapidly become the standard for high-level LLM-browser interaction, providing a bridge that allows models to 'see' and 'click' web elements with minimal code. Unlike traditional scrapers, it utilizes dynamic HTML analysis to simplify the DOM, ensuring that models are not overwhelmed by redundant tags while preserving critical navigation context. A standout feature is the use_vision parameter, which enables agents to interpret UI elements visually—a capability that is revolutionizing how agents handle non-standard layouts.
While browser-use excels at perception-based navigation, it faces distinct trade-offs compared to frameworks like LaVague. While LaVague focuses on generating reusable code and 'World Models' for long-term automation, browser-use is optimized for real-time orchestration, making it more susceptible to latency and resolution scaling issues. Developers are increasingly pairing the library with GPT-4o to manage multi-step workflows like flight comparisons, though experts warn that 'planning walls' still exist for tasks requiring more than 15+ sequential steps.
Llama 3.2 and Phi-3.5 Drive the Shift to Local Agency
The deployment of Small Language Models (SLMs) like Llama 3.2 3B and Phi-3.5 is catalyzing a shift toward truly private, on-device agency. Benchmarks indicate that the Llama 3.2 3B model achieves function-calling performance comparable to much larger 8B models, making it viable for complex local workflows. However, the competitive landscape for local tool-calling is intensifying; 2026 evaluations place Qwen3.5 4B at a 97.5% accuracy rate, followed by Nemotron Nano 4B at 95%.
While these models excel at single-tool selection, multi-tool orchestration remains the primary performance bottleneck for local agents where scores typically diverge. For sectors like healthcare and legal, the ability to run these models via backends like Ollama ensures data stays within secure perimeters while maintaining high reasoning quality. The focus for 2026 is clearly on closing this orchestration gap to make on-device agents as capable as their cloud-based counterparts.
HuggingFace Insights
Stop wrestling with brittle JSON schemas—the future of agency is being written in raw, executable Python.
For the longest time, we’ve treated agents like polite bureaucrats, forcing them to fill out JSON forms before they’re allowed to touch a tool. This week, the industry took a collective step toward a more visceral reality: Code-as-Action. Hugging Face’s smolagents is leading a rebellion against the 'prompt-chaining' status quo, proving that giving an agent a compiler is significantly more efficient than giving it a template.
But as we empower agents to write their own tools, we’re hitting a sobering 'industrial reality.' While we can now scale reasoning chains to over 10,000 tokens with frameworks like FIPO, the latest benchmarks from IBM and Berkeley show a humbling 20% success ceiling for complex IT tasks. The bottleneck isn't just intelligence; it's recovery. We are building agents that can think deeper than ever, yet 31.2% of failures occur because they don't know how to ask for help when a Kubernetes cluster bites back. Today’s issue explores this tension between the architectural elegance of minimalist frameworks and the messy, high-stakes requirements of production-grade autonomy.
The Death of JSON: Smolagents and the Code-Centric Shift
The era of the brittle JSON schema is ending. Hugging Face has introduced smolagents, a minimalist framework that treats agentic actions as executable Python snippets rather than structured text. This 'code-as-action' philosophy isn't just cleaner—it's demonstrably more effective, showing a 30% reduction in operational steps compared to traditional prompt chaining. The framework's architectural superiority was solidified by the Transformers Code Agent, which achieved a 0.43 SOTA score on the GAIA benchmark by allowing agents to write and run their own tools.
This isn't just for massive clusters, either. The 'Tiny Agents' initiative proves that functional, tool-enabled agents can be deployed in as few as 50-70 lines of code using the Model Context Protocol (MCP). With expanded support for Vision-Language Models (VLMs) and deep tracing via Arize Phoenix, the ecosystem is moving toward a 'less is more' approach where the agent's logic is as readable as the code it generates.
Open-Source Deep Research Challenges the Search Giants
The 'black box' of proprietary search agents is being dismantled by the open-source community. A new huggingface initiative, powered by smolagents and DeepSeek-R1, has hit a 67.4% GAIA benchmark score, matching the performance of closed-source alternatives while keeping the data in the developer's hands. This modular shift is supported by Together AI’s multi-hop reasoning architectures, which synthesize massive reports from complex web queries without the high per-request overhead of commercial APIs.
Practical implementations like MiroMind are already utilizing the MiroThinker agent to execute autonomous 'thinker' loops. These systems are capable of generating technical reports exceeding 20 pages by breaking tasks into structured pipelines. By leveraging flexible backends like Tavily and local storage solutions like DeepSearcher, developers are finally gaining the transparency needed for high-stakes research.
The 20% Ceiling: Why Industrial Reliability is Still Out of Reach
As agents move from playgrounds to production, they are hitting a wall. A collaboration between IBM Research and UC Berkeley has introduced IT-Bench, revealing a humbling 20% success ceiling for agents managing complex systems like Kubernetes. Their research identifies a critical flaw: 31.2% of failures stem from an inability to recover from initial errors. According to the Multi-Agent System Failure Taxonomy (MAST), agents often suffer from 'Premature Task Abandonment' or a simple failure to ask for clarification when things go south.
To address this, the industry is moving toward more granular diagnostics. IBM Research launched AssetOpsBench to test policy-compliant execution, while Adyen introduced DABStep to measure reasoning depth over pattern matching. These tools are designed to move us toward the 90%+ reliability required for enterprise use, shifting the focus from binary 'pass/fail' metrics to nuanced planning diagnostics.
Scaling Reasoning: From Token Chains to Physical World Action
New training frameworks are pushing the boundaries of how long an agent can 'think' before it acts. The FIPO framework is redefining credit assignment, scaling reasoning chains from a baseline of 4,000 tokens to a deep-reasoning regime exceeding 10,000 tokens. By optimizing policies based on future outcomes, FIPO allows models to move beyond simple pattern matching into verifiable multi-step planning.
Meanwhile, nvidia is taking this reasoning to the physical world with Cosmos Reason 2, which uses synthetic data from Isaac Sim to enable long-horizon reasoning in robotics. This transition from 'prompted' to 'trained' autonomy is mirrored in the software space by huggingface and their Jupyter Agent 2.0, which optimizes models specifically for notebook execution, and LinkedIn's work on applying agentic RL to open-source models.
The GUI Frontier: Low-Latency Agents for the Desktop
The race to automate the desktop is heating up with the release of ScreenSuite, a diagnostic toolset containing 100+ tasks for ranking VLMs. Specialized models like the Holotron-12B are prioritizing speed, achieving a throughput of 8.9k tokens/s to ensure low-latency interaction. In the benchmarking wars, the Writer’s Action Agent recently claimed a 10.4% score on the Computer Use Benchmark (CUB), currently the highest recorded overall.
To bridge the gap between training and deployment, the ScreenEnv framework now allows for full-stack desktop agent testing in sandboxed environments. This ecosystem approach—pairing specialized models like Smol2Operator with robust evaluation—is critical for moving GUI agents toward reliable workplace automation.
Vertical Agency: Moving Beyond Generalist Chat
Agentic applications are specializing into high-stakes industries like healthcare and data analysis. Google's google EHR Navigator Agent, built on MedGemma, autonomously navigates longitudinal health records, a development supported by the new MedAgentBench published in NEJM AI. These systems are designed to interact directly with FHIR APIs, turning clinical queries into executable actions.
In the data sector, the nolanzandi Virtual Data Analyst is gaining traction for its ability to explore structured databases autonomously. Even complex mathematics is getting the agent treatment; Intel’s huggingface DeepMath agent uses the smolagents framework to tackle formal proofs, signaling a broad pivot toward verifiable, domain-specific execution.
The Generalist Foundation: AI vs. AI and the JAT Model
Hugging Face is accelerating multi-agent intelligence through competition and foundation models. The ⚔️ AI vs. AI ⚔️ system, launched by Thomas Wolf, uses Elo ratings and self-play to discover emergent strategies in adversarial environments. Simultaneously, the Jack of All Trades (JAT) model is emerging as a potential 'GPT-2 moment' for embodied AI. Trained on a massive dataset spanning Atari, robotics, and simulations, JAT aims to prove that a single transformer can generalize across 100+ disparate action spaces, bridging the gap between digital reasoning and physical interaction.