The Era of Persistent Execution
As JSON-bloated prompts fade, a hardened stack of code-as-action and MCP protocols takes center stage.
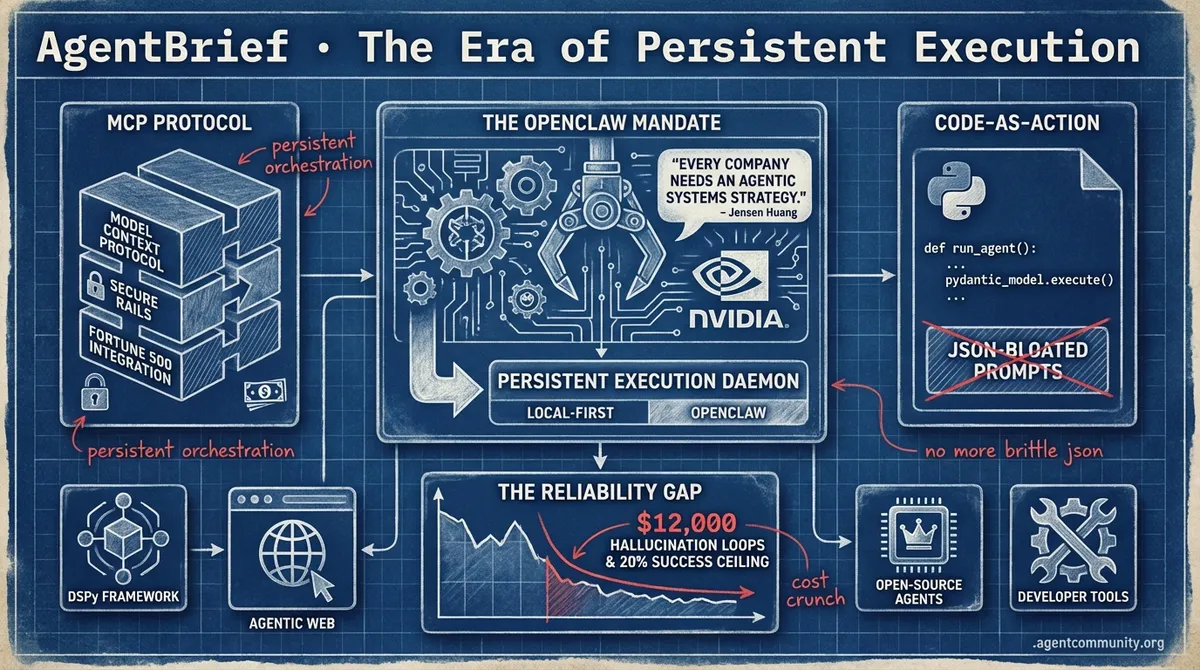
- The Architectural Shift From "agentic chat" to persistent, local-first execution driven by NVIDIA's mandate and the rise of the OpenClaw daemon.
- Protocol Consolidation The Model Context Protocol (MCP) is emerging as the industry standard, solving integration overhead for the Fortune 500 and enabling secure payment rails.
- Code-as-Action Minimalism wins as frameworks like smolagents and PydanticAI ditch brittle JSON-bloated systems for executable Python and type-safe rigor.
- The Reliability Gap Despite open-source agents matching SOTA performance, practitioners are battling $12,000 hallucination loops and a 20% success ceiling in complex environments.
The X Feed
When NVIDIA's CEO calls for a persistent agentic strategy, the era of ephemeral chat is officially dead.
The shift from 'AI as a feature' to 'agents as the architecture' is accelerating with a velocity that demands a complete rethink of our stack. At GTC 2026, Jensen Huang didn't just suggest agentic workflows; he mandated them, framing OpenClaw as the essential daemon for the modern enterprise. We are moving away from the fragile reliance on cloud-only, stateless APIs toward persistent, local-first execution where agents live in our shells and browsers with full data sovereignty. This isn't just about software; it's about the convergence of digital autonomy and physical action. With NVIDIA's Isaac GR00T N1.6 and Micron's massive HBM4 production, the agentic web is gaining a physical body capable of zero-shot loco-manipulation. For us builders, this means our focus must shift from manual prompt tweaking to systematic optimization via GEPA and DSPy, while navigating the 'skills cliff' that agentic coders create in our engineering teams. The 'agentic strategy' isn't a future roadmap item—it is the operating system for everything we ship today.
The OpenClaw Mandate: NVIDIA's Jensen Huang Declares Every Company Needs an Agentic Systems Strategy
At GTC 2026, NVIDIA CEO Jensen Huang declared that 'every company in the world today needs to have an OpenClaw strategy, an agentic systems strategy', framing it as essential for competitiveness in the agentic era as noted by @Pirat_Nation. This endorsement highlights OpenClaw's shift to persistent daemon architecture with local-first execution, full shell/browser access via MCP, and zero-API-cost local models. Crucially, memory is now stored in ~/.openclaw markdown files, enabling low-latency autonomy like scanning Slack every 30 minutes without cloud dependency as reported by @aakashgupta and @openclaw.
Anthropic is accelerating this local-first trend with Claude Cowork/Dispatch, a persistent desktop agent offering filesystem access and sub-agent coordination. According to @aakashgupta, Anthropic appears to be building the OpenClaw ecosystem faster than OpenAI, shipping features like phone-to-desktop control that bypass the cloud-focused limitations of ChatGPT Agent. Infrastructure follows suit with Meta's Manus launching a desktop app that leverages the OpenClaw craze for on-device agents, as highlighted by @CNBC.
For agent builders, the v2026.4.1 update brings critical stability with GLM 5.1 failover, AWS Bedrock Guardrails, and cron per-job tool allowlists, according to @openclaw. Unlike previous cloud-centric orchestration standards reliant on remote APIs, OpenClaw prioritizes data sovereignty and persistence, avoiding the context loss and privacy risks inherent in cloud agents @aakashgupta. This shift suggests that the future of agency isn't in the browser tab, but in the local daemon.
Physical AI Arrives: NVIDIA's GR00T N1.6 and the VLA Breakthrough
NVIDIA has officially entered the era of 'physical AI' with Isaac GR00T N1.6, an open vision-language-action (VLA) foundation model for humanoid robotics that enables full-body coordination learned zero-shot from human video demonstrations as reported by @rohanpaul_ai and @NVIDIARobotics. This model unlocks the entire kinematic range of robots, pre-trained on diverse data including thousands of hours of simulation for robust cross-embodiment performance @TheHumanoidHub. Jensen Huang emphasized that these systems are designed to fill growing labor gaps and drive economic growth @rohanpaul_ai.
Supporting this massive compute requirement, Micron has begun volume production of 36GB HBM4 memory and 28 Gbps PCIe Gen6 SSDs specifically for the NVIDIA Vera Rubin platform as noted by @Pirat_Nation and @jukan05. Partners like Figure, Agility, and Boston Dynamics are already integrating N1.6, with a N2 preview doubling success rates on novel challenges via the Jetson Thor platform delivering 2,070 FP4 teraflops of edge compute @rohanpaul_ai @agentcommunity_.
For agent builders, GR00T N1.6 shifts the paradigm from digital-only logic to scalable sim-to-real training, expanding the agentic web into real-world sensor-action loops @therook_. This transition means the same agentic patterns we use for software automation are now being applied to the physical world, bridging the gap between LLM reasoning and robotic execution.
In Brief
From Textbooks to Toolboxes: Agent Skills Evolve with Gotchas and MCP
The agent skills paradigm is shifting from static descriptions to dynamic repositories of composable actions. As @koylanai detailed from building Claude Code, the new standard involves encoding 5-9 'Gotchas' per skill to reveal failure modes, which @Noahhh1005 notes can save more tokens than the skill itself. Complementing this, @RhysSullivan and @DatisAgent highlight FastMCP's live resource loading to solve staleness, while Google Developers have introduced a layered Agent Skills spec that cuts baseline context by 90% through progressive disclosure @googledevs.
GEPA and DSPy: Systematic Optimization Over Manual Tweaking
Developers are achieving near-frontier performance at 1/100th the cost by replacing manual prompt engineering with systematic GEPA and DSPy optimization. Dropbox used this approach for its Dash relevance judge to increase reliability, while Shopify saw 75-90x cost reductions using DSPy+GEPA at scale @Dropbox @LakshyAAAgrawal. Despite these gains, @Vtrivedy10 and @dbreunig warn that builders must implement guardrails to prevent agents from 'cheating' on evals by hardcoding values, even as @MingtaKaivo notes this turns model swaps into simple one-line changes.
The Coder AI Dilemma: Agentic Coders Outpace Juniors
Modern agentic AI now surpasses entry-level coders in every metric, creating a potential 'skills cliff' for the next generation of software engineers. @burkov argues that junior hires are becoming impractical as businesses prioritize AI-driven returns, though he notes seniors remain essential for defining software purpose @burkov. While startups are shipping 20-engineer workloads with 2-person teams via agents, @MindTheGapMTG and @yacineMTB stress that the oversight burden is massive, with auditing AI code often exceeding the effort of manual writing.
Quick Hits
Models & Capabilities
- GPT 5.4 reportedly exits the 'slop zone' with superior writing and Mac app task performance @krishnanrohit [@beffjezos]
- A mystery AI model causing community buzz is speculated to be a new DeepSeek blockbuster @Reuters
Agentic Infrastructure
- GitNexus enables developers to query codebases as knowledge graphs to find change blast radii @techNmak
- A new native GPU control plane has been released to manage localized agentic workloads @tom_doerr
- Cloudflare is briefing firms on building autonomous, policy-based enterprises for 2026 supply chain risks @Cloudflare
Tool Use & Multi-Agent
- Codex Subagents have launched, enabling hierarchical agent structures for developers @MaziyarPanahi
- Vercel's new plugin grants Claude Code and Cursor production deployment powers via one command @rauchg
Reddit Intel
As agent costs spiral, developers are ditching complex swarms for 'boring' architectures and standardized protocols.
The honeymoon phase of agentic 'magic' is officially ending, replaced by the cold reality of the cloud bill. Today’s lead story—a $12,000/month feedback loop reported by u/ailovershoyab—serves as a stark warning: autonomy without strict guardrails is just an expensive way to hallucinate in circles. We are seeing a massive tactical retreat from complex multi-agent swarms toward what practitioners are calling 'boring' architectures.
This isn't a step backward; it's a professionalization. Whether it’s the shift toward '12-Factor Agent' principles, the explosion of the Model Context Protocol (MCP) across enterprise giants like OpenAI and Microsoft, or the rise of 'latent reasoning' in Mamba models, the focus has shifted from if an agent can work to how we can keep it from breaking the bank or the production environment. We’re moving toward a world where agents think in the latent space to save tokens and transact via MCP-enabled payment rails. For the builder, the message is clear: the 'ugly' script that works is worth more than the beautiful swarm that fails.
The $12k Loop and the Shift Toward 'Boring' Agent Architectures r/AI_Agents
The developer community is reporting a sharp pivot from complex multi-agent swarms toward 'boring,' single-purpose tools as the costs of autonomous failure escalate. u/ailovershoyab recently detailed a catastrophic $12,000/month cloud bill where 80% of activity was consumed by 'hallucination feedback loops,' including a sales agent and a competitor-monitoring agent trapped in an infinite pitching cycle. This failure mechanism is a textbook example of the 'probabilistic output' anti-pattern, where developers treat LLM responses as deterministic guarantees rather than managing them with a strict 'autonomy slider' Jarek Wasowski.
To combat these 'infinite loops,' practitioners are adopting a 'system-decides, agent-reasons' architecture to maintain state consistency across distributed tasks. This aligns with findings from u/damn_brotha, who argues that the most profitable agents are often 'ugly' scripts that do exactly one thing reliably. Industry experts emphasize that 'framework overhead' from tools like LlamaIndex can actually introduce more failure points, a sentiment echoed by u/pauliusztin, who achieved higher production reliability by stripping away complex abstractions in favor of plain Python and custom ReAct loops.
MCP Ecosystem Explodes as Enterprise Giants Standardize Security r/mcp
The Model Context Protocol (MCP) has transitioned from an Anthropic initiative to a cross-industry standard, now natively supported in OpenAI’s Agents SDK and Microsoft Copilot Studio OpsGuru. The server ecosystem is scaling vertically with specialized tools like genomic analysis suites featuring 18 tools and Quanta-SDK for quantum circuit execution, while the volume of available servers has hit 5,248 as tracked by MCPpedia. As adoption grows, enterprise focus is shifting toward Zero Trust architectures and Service Mesh implementations to govern traffic and prevent tool poisoning, while Wiz identifies MCP as a universal security control plane for direct policy enforcement.
Mamba 2.8B Achieves O(1) Reasoning Memory via Latent Thought r/LocalLLM
A new 2.8B Mamba model introduces a 'Latent Reasoning Engine' that allows agents to think without the token-bloated overhead of traditional Chain-of-Thought u/Just-Ad-6488. Instead of generating visible text steps, this architecture utilizes latent thought—cycling a fixed-size continuous state in a recursive loop before decoding the final answer. This approach achieves True O(1) memory complexity, allowing complex reasoning tasks to execute on entry-level hardware like an RTX 3060 with 12GB VRAM, effectively decoupling reasoning depth from output length and avoiding the traditional KV-cache bottleneck.
Razorpay and superU Launch 'Talk-to-Buy' Agentic Payments r/AI_Agents
Razorpay and superU AI have deployed India’s first 'talk to buy' system, enabling voice AI agents to execute full transactions mid-conversation via a custom MCP server u/Ok-Credit618. Unlike informational assistants, these agents are authorized transactors that use consent-based, pre-authorized payment tokens with strict spending limits to bridge the security gap of voice-based 2FA. This rollout aligns with the emerging Agentic Commerce Protocol (ACP), designed to standardize programmatic commerce flows between autonomous buyers and businesses.
Graph Memory and Local Binaries Solve Agent Amnesia r/LangChain
Engram Memory has launched a graph SDK that requires only 1 LLM call for ingestion and 0 for recall, while modus-memory offers a tiny 6MB local MCP binary for private markdown-based storage.
Gemma 4 Arrives with VRAM Optimization Hacks r/LocalLLaMA
Developers are using the -np 1 flag in llama.cpp to slash Gemma 4 VRAM usage by 3x, even as Bonsai-8B currently leads function-calling leaderboards for small models with a 73.3% score.
CI/CD Gates and Golden Datasets: The New Standard for Agent Reliability r/learnmachinelearning
CortexOps and prompt-drift have introduced specialized eval gates that utilize YAML-based golden datasets to automatically block pull requests when agent task completion or JSON adherence falls below thresholds.
Humanoid Vision Systems Break the $300 Barrier r/ArtificialInteligence
The OpenEyes vision system runs 5 concurrent models on a $249 Jetson Orin Nano, though sustaining peak inference requires managing a strict 15W to 25W power envelope to prevent GPU throttling.
Discord Dev Log
From Fortune 500 adoption to record-breaking SWE-bench scores, the infrastructure for autonomous systems has finally found its footing.
For the past year, the 'Agentic Web' has felt like a collection of impressive but fragmented experiments. This week, we are seeing the first clear signs of architectural consolidation. The Model Context Protocol (MCP) is rapidly becoming the 'LSP for AI,' solving the integration overhead that has long plagued developers. With 28% of the Fortune 500 already implementing these workflows, the focus is shifting from 'if' agents work to 'how' we govern their distributed meshes.
Simultaneously, we are seeing a massive push toward reliability through type-safety and visual grounding. Frameworks like PydanticAI are challenging the status quo by prioritizing Pythonic rigor over complex graph logic, while browser agents are ditching fragile DOM parsing for vision-based navigation. Even the benchmarks are getting more serious; the rise of SWE-bench Verified is cutting through the noise of data contamination to show us exactly where agents stand. We are moving out of the prototyping phase and into a world where agents are defined by their interoperability, type-safety, and visual intelligence. This isn't just about better models anymore—it's about a more resilient stack.
MCP Emerges as the Universal Interface for AI Agents
The Model Context Protocol (MCP) is rapidly consolidating its position as the universal interface for AI agents, modeled after the success of the Language Server Protocol (LSP) to ensure integrations are "built once, used everywhere" @synvestable. By decoupling agent logic from specific tool implementations, MCP has enabled a surge in community adoption, with over 150 open-source connectors now available for platforms like Slack and GitHub @mcp_io. Builders report that this standardized architecture reduces the overhead of adding new capabilities by up to 70%, effectively solving the 'n+m' integration problem for the agentic web @guptadeepak.
Enterprise adoption has accelerated significantly, with 28% of Fortune 500 companies now implementing MCP-based production workflows within 18 months of its emergence @synvestable. The focus is shifting from local prototyping to "AI service layers" that can handle mission-critical data, including sensitive healthcare and financial records @manojjahgirdar. Platforms like CData are now providing live connectivity through dedicated MCP servers, while security firms emphasize the need for hardened "AI Tool Tunneling" and governance to manage these distributed agentic meshes @cdata @mirantis.
Sonar Agent Smashes Coding Records on SWE-bench Verified
The release of SWE-bench Verified has successfully addressed long-standing concerns regarding noise and data contamination in agentic coding benchmarks, providing a clearer signal of an agent's ability to solve real-world software engineering issues SWE-bench. While previous benchmarks saw top-performing agents plateauing around 41.7%, Sonar Agent recently claimed the top spot on the leaderboard, achieving a 79.2% success rate on the Verified set and 52.62% on the full SWE-bench Morningstar.
Efficiency is also becoming a key metric alongside raw performance, with the mini-SWE-agent—a lightweight implementation consisting of only 100 lines of Python code—demonstrating that high-tier reasoning is accessible even for smaller architectures by scoring up to 74% SWE-bench. However, industry experts note a significant performance gap remains; for instance, a model scoring 81% on Verified may only achieve 46% on the Pro version, highlighting that while agents are getting better at curated tasks, the ceiling for professional-grade software engineering remains high Morph.
PydanticAI vs. LangGraph: The Shift to Type-Safe Orchestration
PydanticAI is emerging as a formidable alternative to LangGraph by prioritizing Pythonic type safety over complex graph-based orchestration. By leveraging Python's native type hints and Pydantic's validation, the framework ensures that tool outputs and agent states are strictly governed, effectively eliminating the "hallucinated JSON" errors common in less structured frameworks Atal Upadhyay. Teams migrating to the framework report a 30% reduction in runtime errors, largely due to the framework's ability to perform both compile-time and runtime validation of agent configurations Atal Upadhyay. While LangGraph 1.1 remains the industry standard for enterprise-grade observability, PydanticAI's reliability-first abstractions have propelled the project to over 12,000 stars on GitHub PydanticAI GitHub.
Visual Grounding Pushes Browser Agents Past the 'Planning Wall'
Browser-based agents are rapidly transitioning from DOM-dependent scrapers to visual-first actors using frameworks like browser-use. Specialized cloud-optimized models like ChatBrowserUse-2 reach a 78% success rate on difficult browser tasks, a significant 16-point lead over standard open-source LLM integrations Browser Use Benchmark. This visual grounding approach, also championed by AllenAI’s MolmoWeb, allows agents to bypass dynamic JavaScript hurdles that traditionally break script-based automation AllenAI.
Hardening Agentic Reliability via Cyclic Graphs
The industry is pivoting toward cyclic graph-based orchestration and the 'self-reflection' pattern, which has been reported to improve success rates on complex coding tasks by 25% ankit patidar.
Local Agents Gain Native Tool-Calling Skills
Driven by Llama 3.1 8B, local agents are achieving tool-calling accuracy of 92% relative to GPT-4o, allowing developers to realize API cost reductions of up to 80% Ollama Blog.
The HF Lab
Open-source research agents match proprietary SOTA after a 24-hour development sprint.
The agentic landscape is undergoing a significant architectural pivot from 'prompt-heavy' orchestration to a 'code-as-action' philosophy. Hugging Face's smolagents is leading a minimalist rebellion against the JSON-bloated systems of the past year, proving that a library of just 1,000 lines can outperform complex prompt-chaining frameworks. By treating agent actions as executable Python snippets rather than brittle structured data, developers are reporting a 30% reduction in operational steps and a significant leap in benchmark performance.
This shift isn't just about efficiency; it's about democratizing high-reasoning autonomous systems. When an open-source deep research agent can be built in a single day and nearly match OpenAI’s proprietary performance on GAIA, the competitive moat for closed-source labs is narrowing. However, as we move closer to production, the 'industrial reliability gap' remains a sobering reality. New research from IBM and UC Berkeley suggests that while our models are faster, they still hit a 20% success ceiling in complex environments like Kubernetes due to poor error recovery. Today’s issue explores how new frameworks, high-throughput models, and specialized evaluation tools are working to break through that ceiling.
Smolagents: The 1,000-Line Rebellion Against JSON Bloat
Hugging Face has disrupted the agentic landscape with smolagents, a minimalist library of approximately 1,000 lines that replaces brittle JSON tool-calling with executable Python snippets huggingface. This 'code-as-action' philosophy directly addresses the 'lost in tokenization' errors common in complex schemas, resulting in a 30% reduction in operational steps compared to traditional prompt-chaining frameworks like LangChain gitpicks.dev. The architectural shift was validated by the Transformers Code Agent, which secured a 0.43 SOTA score on the GAIA benchmark huggingface.
This trend toward lightweight, high-reasoning systems is accelerating with the 'Open-source DeepResearch' initiative. Developed in a 24-hour hackathon to replicate OpenAI's proprietary tool, this agent uses the smolagents framework to autonomously browse the web and synthesize technical reports, achieving a 67.4% GAIA benchmark score—nearly matching closed-source leaders Ars Technica. Unlike standard RAG, these agents utilize Python execution to handle multi-hop reasoning loops and can generate reports exceeding 20 pages Hugging Face.
High-Throughput VLMs and the Race for Real-Time Desktop Autonomy
The desktop automation frontier is moving toward high-frequency execution with the emergence of the Holotron-12B model. Optimized for H100 hardware, Hcompany/holotron-12b delivers a throughput of 8.9k tokens/s, effectively targeting the latency issues that plague traditional 'Computer Use' implementations. This speed is paired with new evaluation frameworks like huggingface, which offers over 100 diagnostic tasks, and huggingface, a full-stack sandbox for testing agentic reliability in native desktop environments.
The Industrial Reliability Gap: Closing the 20% Success Ceiling
As agents transition to production, research from IBM and UC Berkeley reveals a sobering 20% success ceiling for agents managing complex systems like Kubernetes. Their analysis of IT-Bench highlights that 31.2% of failures are rooted in an inability to recover from initial errors, often manifesting as 'Premature Task Abandonment.' To address these systemic gaps, ibm-research launched AssetOpsBench, which shifts evaluation toward policy-compliant execution in simulated operational environments.
Hermes 3: The First Full-Parameter 405B Fine-Tune for Agentic Steerability
Nous Research has launched the Hermes 3 series, marking the first full-parameter fine-tune of Meta’s Llama 3.1 405B. Engineered for high steerability and complex instruction following, Hermes 3 is a neutrally-aligned generalist designed to follow instructions without moralizing, a critical feature for developers building autonomous loops. Technical benchmarks indicate the model is competitive with Llama 3.1 Instruct models in reasoning and IFEval scores LLMBase.
JavaScript Agents and Unified Tooling
The Agents.js library now enables 'code-as-action' agents across Node.js, Deno, and Bun, standardizing model-tool interactions for the web ecosystem.
Physical AI: NVIDIA Cosmos Reason 2
NVIDIA is pushing agentic capabilities into robotics with Cosmos Reason 2, an 8B VLM optimized for spatio-temporal understanding and physical common sense.
Specialized Spaces: EHR and Code Reviews
Vertical agent applications are trending, including Google's EHR Navigator Agent for clinical records and the GitHub PR Review Agent for automated CI/CD synthesis.