The Rise of the Executable Web
From desktop takeovers to code-as-action, the agentic stack is moving from chat boxes to system-level execution.
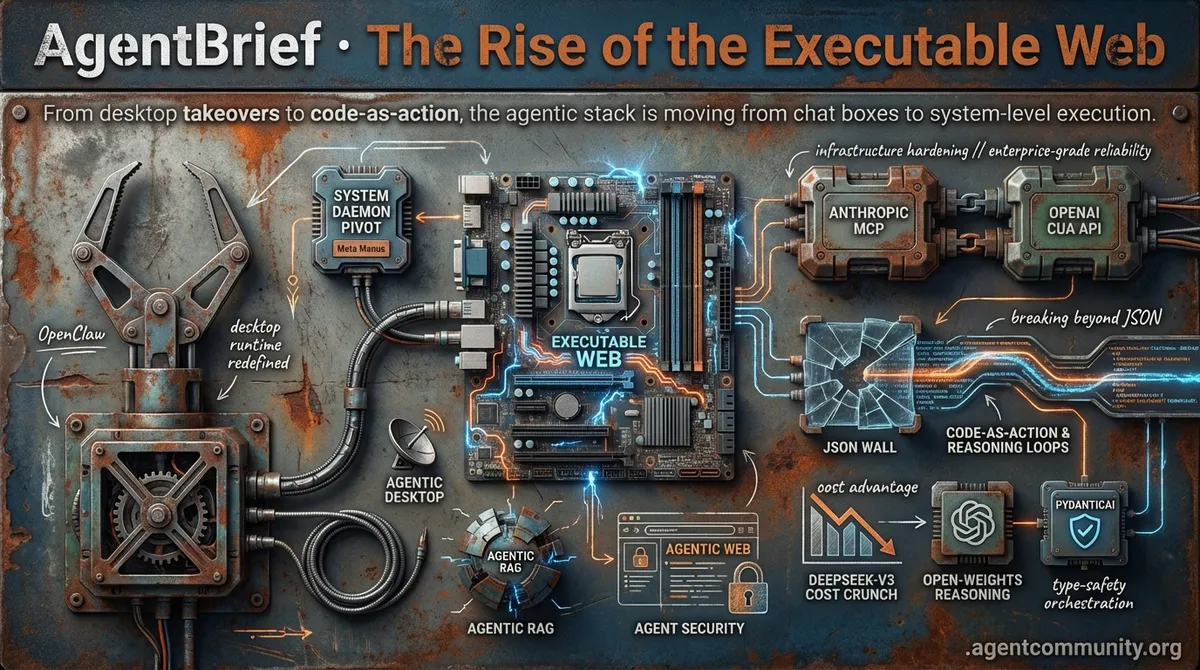
- The Desktop Pivot OpenClaw and Meta’s Manus are moving agents from browser wrappers to local system daemons, redefining the desktop as the primary runtime.
- Infrastructure Hardening Anthropic’s MCP and OpenAI’s CUA API are standardizing data integration and computer use, signaling a shift toward enterprise-grade reliability.
- Economic Disruption DeepSeek-V3’s massive cost advantage is forcing a pivot toward open-weights reasoning, while frameworks like PydanticAI bring type-safety to agent orchestration.
- Beyond JSON The JSON wall is breaking as code-as-action and reasoning loops replace rigid templates to solve high failure rates in complex environments.
The X Intel
Your browser is just a warm-up; agents are taking over the OS and the factory floor.
We are witnessing a fundamental pivot in the agentic web: the migration from cloud-bound wrappers to local, high-agency system daemons. It’s no longer enough for an agent to ‘know’ things; it must execute. This week, the release of OpenClaw v2026.4.5 and the launch of Meta’s Manus 'My Computer' signal that the desktop is the new primary runtime for autonomous systems. Jensen Huang’s declaration at GTC 2026 that every company needs an 'OpenClaw strategy' mirrors the early days of Linux, framing agentic systems as the 'new computer.' For builders, this means moving beyond simple prompt engineering into context engineering and 'toolbox' construction. We’re shifting from teaching models with textbooks to equipping them with modular, failure-aware skills and zero-trust firewalls. Whether it's physical AI through NVIDIA’s Isaac GR00T or local-first automation, the message is clear: the most successful agents will be those that are deeply integrated into the environments where work actually happens. If you aren't building with local execution and safety-first infrastructure in mind, you're building for the past.
The OpenClaw Strategy: Desktop Agents as the New Runtime
OpenClaw v2026.4.5 has arrived, transforming the desktop into a powerhouse for autonomous generation with built-in video and music capabilities from over 9 providers, including OpenAI and Google. The update introduces a critical /dreaming memory consolidation system and enhanced prompt-cache reuse, significantly improving task efficiency @openclaw. However, the ecosystem faces friction as Anthropic reportedly cut off Claude subscriptions for third-party harnesses, forcing a shift toward API keys or alternative models like OpenAI Codex and Qwen @openclaw.
The community is rapidly picking sides in the battle for local dominance. @aakashgupta highlights that demand for local daemons is skyrocketing, evidenced by 318k GitHub stars, and argues that Anthropic's Claude Cowork—with its local VM and mobile-to-desktop control—is currently outpacing OpenAI’s Codex. This momentum is verified by @chrysb, who notes OpenClaw now commands a 66.3% market share of the developer ecosystem.
At GTC 2026, NVIDIA’s Jensen Huang validated this shift, framing the adoption of agentic systems as 'the new computer,' comparable to the rise of Linux @Pirat_Nation. This endorsement sent ripples through the market, causing shares in Chinese 'AI tigers' like Zhipu and MiniMax to surge after being touted as the next generation of ChatGPT-level infrastructure @CNBC.
For agent builders, the focus is now turning toward enterprise-grade security within these local environments. NVIDIA’s NemoClaw is already integrating OpenShell sandboxing to provide the necessary security layers for professional deployment @steipete. As agents move from experimental wrappers to essential system services, the 'OpenClaw strategy' is becoming the standard blueprint for corporate AI integration.
NVIDIA GTC 2026: The Arrival of Physical AI
NVIDIA is officially bridging the gap between digital reasoning and physical action with the unveiling of Isaac GR00T N1.6. This foundation model is a vision-language-action (VLA) powerhouse, designed to let humanoid and industrial robots learn complex, multi-step tasks directly from human video demonstrations @rohanpaul_ai. Early previews of the next-generation GR00T N2 suggest a doubling of success rates on novel challenges, outperforming existing benchmarks like RoboArena @TheHumanoidHub.
To support this hardware-intensive future, the underlying infrastructure is seeing massive upgrades. Micron has entered volume production of 36GB HBM4 and 28 Gbps PCIe Gen6 SSDs specifically for the NVIDIA Vera Rubin platform @Pirat_Nation. These components are expected to deliver 10x efficiency gains in real-time sim-to-real training, allowing agents to process their physical environments with unprecedented speed @MartinSzerment.
Jensen Huang emphasized that these embodied agents are not just technical marvels but economic necessities, designed to fill critical labor shortages and drive growth @rohanpaul_ai. For developers, this signals a massive expansion of the agentic web into robotics, where the 'agent' is no longer just a chatbot but a physical entity operating in three-dimensional space.
From Textbooks to Toolboxes: The Skills Standard Shift
The methodology for building agent intelligence is shifting from 'textbooks' to 'toolboxes.' Developers are moving away from passive model training toward active, composable code repositories. @koylanai recently demonstrated this by rewriting an entire 13-skill repository for context engineering, adding 5-9 'Gotchas' per skill to document common failure modes. This mirrors Anthropic’s internal use of over 700+ skills, where edge cases are treated as vital 'institutional memory' @Hem_chandiran.
The Model Context Protocol (MCP) is the primary engine for this distribution. Tools like FastMCP are now being used to fetch skills as live resources, ensuring that agents are always using the most up-to-date scripts rather than static snapshots @RhysSullivan. Vercel has also joined the fray with an npx plugin delivering 47+ skills with sub-agents for deployments, though builders warn that this convenience comes with a heavy 12k token startup overhead @artiebags.
While these frameworks grant agents 'production superpowers,' the community is sounding the alarm on security and overhead. @RhysSullivan warns that rushed 'skills' can recreate the same outdated documentation issues we see in traditional software. To mitigate this, Anthropic’s MCP Tool Search has reportedly cut overhead by 85% through on-demand discovery, allowing agents to scale their capabilities without drowning in token costs @BretKerr.
In Brief
GEPA and DSPy Enable Systematic Agent Prompt Optimization
Prompt engineering is evolving into an automated, systematic discipline through frameworks like DSPy and GEPA (Generative Evidence-based Prompt Alignment). Dropbox and Shopify have already leveraged these tools to achieve near-frontier performance at 1/100th the cost or 75-90x cost reductions by optimizing smaller models like Qwen @LakshyAAAgrawal @dbreunig. While these loops allow for agent self-evolution—yielding gains up to +39.5% in specialized skills—experts warn that builders must implement strict guardrails to prevent agents from 'cheating' evaluations by hardcoding values @Vtrivedy10 @mr_r0b0t.
Manus Desktop Launches Amid OpenClaw Craze
Meta’s Manus has entered the local agent arena with 'My Computer,' a desktop app designed to give AI agents direct access to local files and system commands. The tool integrates with macOS features like Calendar and Notes via AppleScript, allowing users to build custom launchers and automation apps in under two hours @hidecloud @FellMentKE. This launch intensifies the competition with OpenClaw, offering smartphone remote control and offline functionality to appeal to users seeking local AI sovereignty and personalized software experiences @ChatgptAIskill @imhaoyi.
Hardening Autonomous Workflows with Zero-Trust Firewalls
As AI agents gain shell access and production credentials, the industry is pivoting toward agent-specific security tools like Kavach and OneCLI. Kavach acts as a local Rust-based firewall that intercepts destructive operations and enables temporal rollbacks, while OneCLI provides a gateway for ephemeral secrets to prevent credential exposure @tom_doerr @jonathanfishner. Builders are increasingly advocating for layered safeguards, including human-in-the-loop overrides and deterministic checkpoints, to manage the risks of continuous autonomous execution @AITECHio @GHchangelog.
Conditional Attention Steering via XML Tagging
Advanced context management is moving toward Conditional Attention Steering, using XML patterns like to help agents focus on relevant data. This technique, championed by Muratcan Koylan, instructs models to only process specific blocks when conditions are met, improving instruction adherence in complex workflows @koylanai. As frameworks like Hermes Agent face 'skill bloat,' these selective mechanisms are becoming essential to prevent attention dilution and keep context windows efficient @Teknium @elastic_devs.
Quick Hits
Agent Infrastructure
- GitNexus turns repositories into queryable knowledge graphs with a single command @techNmak.
- Local micro-agents that react to environment changes are in development by @tom_doerr.
- A new native GPU control plane specifically for AI agents has been released @tom_doerr.
Models & Evaluation
- The Unsloth Model Arena now allows side-by-side comparison of fine-tuned vs base models @akshay_pachaar.
- NVIDIA is reportedly preparing Groq chips specifically for the Chinese market @Reuters.
- Speculation grows over a potential mystery DeepSeek blockbuster release @Reuters.
Developer Tools
- A research automation system using n8n and Groq has been open-sourced for paper collection @freeCodeCamp.
- A new self-hosted code review bot powered by Claude is now available via @tom_doerr.
Reddit Engineering Debrief
Open-weights reasoning hits a new price-performance ceiling as orchestration moves toward auditable engineering.
The landscape for autonomous agents is undergoing a fundamental shift from experimental prompts to rigorous engineering. As we see in today’s issue, the emergence of DeepSeek-V3 marks a pivotal moment where open-weights models are not just competing on logic but fundamentally breaking the unit economics of the agentic stack—claiming a 29.8x cost advantage over GPT-4o. This economic pressure is coinciding with a structural pivot in how we build: frameworks like PydanticAI and LangGraph are moving us toward stateful, type-safe architectures that prioritize auditability over ephemeral swarms.
However, this maturity comes with new battlegrounds. We’re seeing the rise of 'Agentic RAG'—where agents aren’t just retrieving data but reasoning through it—and a sobering reality check on security. With indirect prompt injection now ranked as the #1 threat to agentic systems, the 'execution gap' is the new frontier for both builders and adversaries. Today, we dive into the benchmarks, the orchestration wars, and the security protocols defining the next phase of the Agentic Web.
DeepSeek-V3 Outpaces GPT-4o in Coding Benchmarks r/LocalLLaMA
DeepSeek-V3 has established itself as a top-tier contender in the agentic landscape, outperforming proprietary models in critical coding and reasoning benchmarks. On the HumanEval-Mul (Pass@1) benchmark, the model achieved a score of 82.6%, surpassing both Claude 3.5 Sonnet (81.7%) and GPT-4o (80.5%). This performance is underpinned by a 671B parameter Mixture-of-Experts (MoE) architecture that utilizes Multi-Head Latent Attention (MLA) to maintain high efficiency despite its scale.
Beyond raw logic, the model's economic profile is a major disruptor for autonomous systems; it is estimated to be 29.8x less expensive than GPT-4o for input and output tokens. While community reports on r/LocalLLaMA claim an unverified 93.2% success rate in planning tasks, technical reviews emphasize its dominance in LiveCodeBench. This combination of high-tier reasoning and low-cost orchestration marks a significant shift toward open-weights models for production-grade agent stacks.
PydanticAI vs. LangChain: The 'AI as Engineering' Pivot r/AI_Agents
PydanticAI is rapidly gaining traction by promoting an 'AI as engineering' philosophy, contrasting with LangChain's more abstracted, chain-centric architecture. While community estimates suggest a 35% reduction in runtime errors, the framework's primary draw is its strict reliance on Python type hints, providing a more predictable development cycle than traditional string-heavy prompts. Observability is a key differentiator, with PydanticAI utilizing OpenTelemetry and Logfire, whereas LangChain typically relies on its proprietary LangSmith ecosystem.
Technical trade-offs are emerging in community evaluations like those found on r/AI_Agents. LangChain remains superior for rapid prototyping of complex tool-calling via its @tool decorator, which automatically generates schemas from function signatures. Conversely, PydanticAI is being hailed as ideal for high-integrity environments like healthcare or finance where validation is the primary bottleneck, though it currently faces limitations in sophisticated tool-calling loops compared to LangChain's mature orchestration layers.
LangGraph Checkpointers Bring 'Time Travel' to Workflows r/LangChain
LangChain’s LangGraph has solidified its position as a low-level orchestration framework by standardizing its persistence layer through the new langgraph-checkpoint-conformance interface. This system enables agents to maintain persistent state across multi-actor workflows, which is now being utilized for high-stakes legal solutions requiring strict compliance and governance. Practitioners on r/LangChain report that the ability to 'time travel'—rewinding and forking state history—is the primary differentiator for moving complex autonomous agents into production.
The checkpointer system specifically addresses the 'execution gap' by facilitating human-in-the-loop patterns, allowing agents to pause for approval without losing context. This architectural shift follows the broader industry trend of 'boring' but reliable agent designs. As @LangChainAI has signaled, the industry is moving away from ephemeral swarms toward stateful, auditable graphs that allow for precise control over agentic behavior.
Agentic RAG: From Linear Pipelines to Reasoning Loops r/ArtificialIntelligence
The industry is rapidly moving beyond static retrieve-then-generate flows toward Agentic RAG, an architecture where autonomous agents use tools to iteratively search, verify, and refine their own context. Unlike traditional pipelines that struggle with multi-step information needs, Agentic RAG layers in reasoning agents that plan and adapt retrieval strategies in real-time. This transition has reportedly led to a 25% improvement in factual accuracy for complex queries, as practitioners on r/ArtificialIntelligence leverage self-correcting patterns to identify irrelevant data.
Architectural patterns are maturing around 'adaptive intelligence' frameworks that complement standard RAG with autonomous learning. These systems address the execution gap by allowing agents to decide when to trigger a new search or validate a claim before generating a response. By moving from a fixed context window to a dynamic tool-use loop, enterprise systems are finally overcoming the long-standing challenges of ambiguous search and knowledge silos.
Indirect Injection Ranked #1 Threat to Agentic Systems r/mcp
As agents transition to autonomous web-browsing, security researchers are sounding the alarm on indirect prompt injection—now dubbed the 'XSS of the AI Agent Era.' This vulnerability, where hidden instructions in external websites hijack an agent’s tool-calling capabilities, has officially been ranked the #1 threat in the 2025/2026 OWASP Top 10 for LLM Applications. A 2026 benchmark study confirms that 70% of tested agent frameworks were susceptible to instruction overrides when processing untrusted environmental data.
To mitigate these risks, the developer community is pivoting toward 'agentic firewalls' and the BDSMCP (Bidirectional Secure MCP) protocol. As u/glamoutfit discussed on r/mcp, this protocol implements mandatory handshakes to verify tool integrity before an agent executes external instructions. This is a critical response to observations from Palo Alto Networks’ Unit 42, which has already seen these attacks occurring in the wild.
Open Interpreter 0.4 and the Hardening of Local Execution r/LocalLLaMA
Open Interpreter's version 0.4 update marks a shift toward more robust local agentic control, reportedly achieving a 40% reduction in execution latency for desktop tasks. While these speed gains facilitate real-time AI coworkers, the security landscape for local execution is becoming increasingly complex. Researchers have identified that self-hosted runtimes are now primary targets for 'execution boundary' attacks, where agents ingest untrusted text that triggers malicious code execution.
Current best practices for local-first architectures now mandate Zod-based input validation and strict path allowlists to prevent agents from traversing sensitive directories. This is critical given that marketplaces like ClawHub have already seen over 1,184 malicious skills designed to exfiltrate data. Furthermore, new research warns of Unicode homograph attacks, which boast an 85% success rate in bypassing agent security filters by spoofing trusted file names.
Discord Dev Dispatch
OpenAI's CUA and Anthropic's MCP are turning the agentic web into a production reality.
We have moved past the demo-ware phase of AI agents. Today's developments signal a shift from simple chatbots to autonomous systems with real-world capabilities. OpenAI's Operator is moving into the enterprise via a dedicated Computer-Using Agent (CUA) API, while Anthropic’s Model Context Protocol (MCP) has effectively become the USB port for data integration, already adopted by nearly a third of the Fortune 500. The narrative is clear: the infrastructure for the agentic web is hardening. We are seeing a flight to reliability across the stack—from PydanticAI’s type-safe validation to LangGraph’s stateful persistence. Even small models like Phi-4 are being repurposed as high-precision routers rather than general-purpose toys. As benchmarks like GAIA see scores jump from the 40s to the 70s, the persistent planning wall is finally showing cracks. For builders, the message is simple: the tools are ready, the standards are set, and the autonomous desktop is no longer a research project—it is an API call away.
OpenAI Operator: From Pro Preview to Enterprise CUA API
OpenAI's Operator has officially transitioned from a text-based assistant to a visual agent, utilizing a specialized Computer-Using Agent (CUA) architecture designed to navigate browsers and execute multi-step tasks @openai. While currently available as a research preview for Pro users in the U.S., OpenAI has confirmed plans to release a dedicated API for the CUA model, allowing developers to integrate these autonomous browser capabilities into their own applications @constellationr.
Early high-performance benchmarks like WebVoyager (87%) contrast with longitudinal data from early 2026, which places real-world task success rates closer to 43% due to a persistent 'planning wall' in complex sequences. Furthermore, leaks from @tibor_blaho indicate that this CUA architecture is already being integrated into the ChatGPT Mac app for direct desktop and browser control.
Model Context Protocol Becomes the USB Port for Enterprise AI
Anthropic’s Model Context Protocol (MCP) has officially transitioned from an experimental framework to the 'USB port' for the agentic web, enabling secure connections between data sources and AI agents Anthropic. By standardizing how models interact with tools like GitHub and Slack, MCP has enabled developers to achieve a 40% reduction in integration boilerplate code Synvestable. This architectural decoupling solves the persistent 'n+m' integration challenge that previously hindered scaling Thomas Heidloff.
The protocol's maturity is reflected in its rapid enterprise penetration, with 28% of Fortune 500 companies now deploying MCP-based production workflows as of early 2026 Synvestable. Industry leaders are positioning 2026 as the year for 'enterprise-ready' adoption, as organizations move toward standardized AI service layers that prioritize security and interoperability over custom, brittle wrappers CData.
PydanticAI Hardens Agentic Logic with Type-Safe Validation
PydanticAI is redefining agent orchestration by prioritizing Pythonic type safety, a move that developers report has led to a 30% reduction in runtime errors Atal Upadhyay. By leveraging Pydantic models to strictly validate tool calls and model outputs, the framework mitigates 'hallucinated JSON' errors and provides a Rust-like 'if it compiles, it works' development experience Pydantic AI GitHub.
Production-grade reliability is further bolstered by integration with Pydantic Logfire, an OpenTelemetry-based observability tool. Real-world applications include Datalayer, which adopted the framework to build a multi-protocol agent platform, and Lema AI, which utilizes its structured output validation for complex tool-calling workflows Pydantic Case Studies. With features like Dependency Injection, PydanticAI allows for systematic testing of agentic systems in high-entropy enterprise data hubs Agents Index.
LangGraph Hardens Agentic Reliability with Stateful Persistence
LangGraph has solidified its position as the successor to the deprecated AgentExecutor—which is scheduled for EOL in December 2026—by prioritizing explicit state management over simple linear chains Digital Applied. The framework's Postgres-backed checkpointer allows agents to persist state across multi-agent workflows, enabling 'time-travel' debugging and seamless recovery from failures or human-in-the-loop (HITL) interruptions Prasun Mishra.
This deterministic approach is essential for production-grade autonomous systems requiring auditable execution paths. By decoupling the reasoning model from the stateful persistence layer, developers are now building 're-entrant' agents that can 'sleep' during long-running tasks and resume with 100% state fidelity, providing significantly better reliability than ad-hoc RAG or pure vector approaches SparkCo AI.
Phi-4 Anchors the Shift Toward High-Precision Edge Routing
Microsoft's release of Phi-4 has redefined the performance ceiling for Small Language Models (SLMs), positioning them as high-precision 'routing' agents. While GPT-4o-mini remains a versatile generalist, Phi-4 demonstrates superior specialized reasoning in STEM and logic-heavy tasks, achieving a score of 75.5 on key benchmarks Mehul Gupta.
On mathematical benchmarks like GSM-8K, the Phi-4-mini variant has recorded an 88.6% success rate, outperforming the majority of 8-billion-parameter models despite its smaller footprint VentureBeat. Industry focus has shifted to Phi-4’s use of synthetic datasets to harden its reasoning, making it a more 'deterministic' choice for edge-based orchestration compared to broader multimodal capabilities Analytics Vidhya.
New Benchmarks Target Long-Horizon Agentic Planning
Evaluation is shifting from static Q&A to long-horizon planning as frameworks like AgentBench incorporate interference scenarios where environments change mid-task THUDM. Recent leaderboard shifts indicate a massive leap in reasoning capabilities; while early 2026 benchmarks saw GPT-5 Mini at 44.8%, the latest data shows Claude Sonnet 4.5 commanding a 74.6% success rate AwesomeAgents.
Furthermore, H2O.ai has reportedly reached a 75% score on GAIA, representing the first 'C Grade' performance in the benchmark's history Agentic Design. This surge suggests that while long-horizon planning is still a bottleneck, the industry is rapidly closing the reliability gap through improved agentic design patterns and refined metrics focusing on trajectory efficiency HAL.
HuggingFace Research Hub
Hugging Face challenges OpenAI's deep research dominance as benchmarks reveal a 20% success ceiling for agentic ops.
The 'Agentic Web' is undergoing a fundamental architectural pivot. For the past year, builders have struggled to force-fit autonomous behavior into rigid JSON schemas, and we are finally hitting a wall. New industrial data is sobering: today's most sophisticated agents fail 80% of the time when managing complex environments like Kubernetes. The diagnostic is clear—most failures occur because agents cannot recover from their first mistake, leading to 'Premature Task Abandonment.'
However, the solution is emerging from two fronts. First, Hugging Face is leading a 'code-as-action' revolution with smolagents, proving that giving an agent a Python compiler is 30% more efficient than a template. Second, we are seeing the proprietary 'Deep Research' black box crack wide open. In a single 24-hour sprint, the open-source community matched OpenAI’s performance using transparent, auditable reasoning loops. We aren't just building faster agents; we are building systems that can finally 'think' through execution errors via Reinforcement Learning and standardized protocols like MCP. Today’s issue explores why the future of agency isn't just about the model—it’s about the loop.
The Code-as-Action Revolution: Smolagents and Open Deep Research
Hugging Face has disrupted the agentic landscape with smolagents, a minimalist library that replaces brittle JSON tool-calling with executable Python snippets. This 'code-as-action' philosophy addresses the 'lost in tokenization' errors common in complex schemas, resulting in a 30% reduction in operational steps compared to traditional frameworks. The shift was validated by the Transformers Code Agent, which secured a 0.43 SOTA score on the GAIA benchmark, proving that a compiler is more efficient than a template.
This architecture is already powering the next wave of transparency. Developed in a 24-hour sprint following OpenAI's recent launch, the Open Deep Research initiative achieved a 67.4% GAIA score, matching closed-source leaders. By treating search as an autonomous 'thinker' loop and utilizing models like DeepSeek-R1, the system generates technical reports exceeding 20 pages with fully auditable reasoning chains, as seen in community implementations like MiroMind.
The 20% Success Ceiling: Diagnosing Failure in Industrial Ops
New frameworks like IT-Bench and the Multi-Agent System Failure Taxonomy (MAST) have revealed a humbling 20% success ceiling for agents managing complex environments. A study by ibm-research and UC Berkeley found that 31.2% of failures occur because agents cannot recover from their first mistake. To bridge this gap, LinkedIn is pioneering 'Agentic RL,' using iterative feedback loops and PPO to improve recovery from failed API calls, while Adyen uses its DABStep benchmark to ensure agents aren't just relying on shallow pattern matching.
Desktop Autonomy: High-Throughput VLMs and GUI Benchmarks
The frontier of computer-use is shifting toward real-time GUI interaction, powered by specialized Vision-Language Models (VLMs) like Hcompany/holo1. To facilitate fluid control, Hcompany/holotron-12b has set a new bar for throughput, achieving 8.9k tokens/s on H100 hardware. This hardware-accelerated autonomy is supported by the release of Hugging Face/screensuite, an evaluation platform featuring 100+ diagnostic tasks designed to stress-test an agent's ability to interpret complex UI elements across operating systems.
Beyond Python: MCP and Agents.js Standardize the Agentic Web
The Model Context Protocol (MCP) is transforming agentic data interaction by enabling dynamic tool discovery, allowing 'Tiny Agents' to be deployed in as few as 50-70 lines of code huggingface.
Local Intelligence: Speculative Decoding and Pruned Models
Speculative decoding on Intel Core Ultra processors via intel/qwen3-agent is accelerating local agent generation by 1.3x using a depth-pruned 0.6B draft model.
Edge Agency: JavaScript Support and MLX Quantization
The launch of huggingface/agents-js brings code-as-action to Node.js and Deno, while deadbydawn101 released 4-bit MLX variants of Gemma-4 for local tool-calling.