From Chatbots to Agentic Systems
As frameworks harden and local models dominate, the agentic web moves from ephemeral chats to persistent, code-first execution.
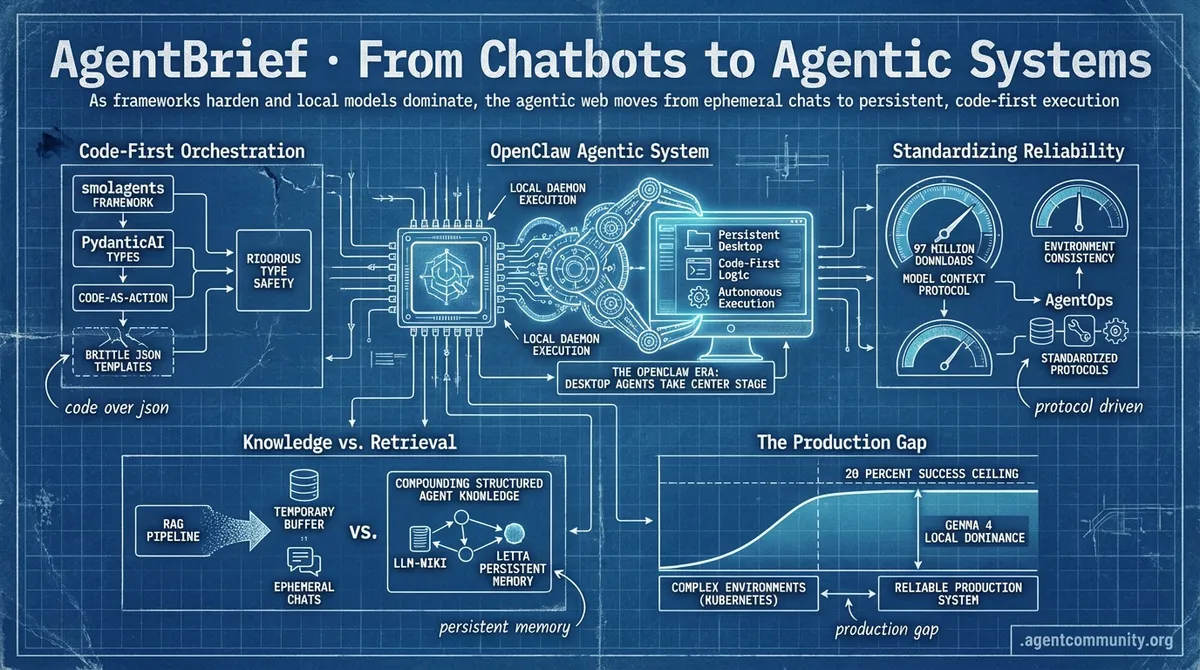
- The Persistent Desktop NVIDIA and Jensen Huang's OpenClaw vision signals a shift toward local-first agentic daemons that replace traditional side-panel copilots with autonomous system execution.
- Code-First Orchestration Frameworks like smolagents and PydanticAI are pushing the industry away from brittle JSON templates toward code-as-action logic and rigorous type safety.
- Standardizing Reliability With the Model Context Protocol hitting 97 million downloads and the rise of AgentOps, builders are prioritizing environment consistency and standardized communication protocols over manual prompt engineering.
- Knowledge vs. Retrieval Andrej Karpathy's LLM-Wiki and Letta's persistent memory breakthroughs suggest a transition from ephemeral RAG pipelines to compounding, structured agent knowledge.
- The Production Gap Despite Gemma 4's local dominance, a 20 percent success ceiling in complex environments like Kubernetes reminds practitioners that closing the gap between a demo and a reliable production system remains the ultimate challenge.
The Agentic Desktop
Stop writing one-off prompts and start building persistent, local-first agentic daemons.
The era of the 'copilot' as a side-panel chat is officially ending. As Jensen Huang declared at GTC 2026, we are entering the 'OpenClaw' era, where the agentic system is the new computer. This isn't just marketing fluff; we are seeing a massive shift toward persistent local daemons that control our desktops and vision-language-action (VLA) models that control physical hardware. For agent builders, the focus has pivoted from 'how do I prompt this?' to 'how do I architect the infrastructure for autonomous execution?' Whether it is NVIDIA’s NemoClaw bringing zero-default sandboxing to the enterprise or the systematic optimization of DSPy and GEPA replacing manual prompt engineering, the message is clear: the stack is maturing. We are moving away from fragile, hand-tuned prompts toward robust, optimized agentic workflows that can navigate codebases with GitNexus and operate robots via Isaac GR00T. If you aren't building for local-first persistence and systematic reliability, you're building for the past. Today’s issue explores the tools and patterns defining this new agentic web.
The OpenClaw Era: Desktop Agents Take Center Stage
The 'OpenClaw' paradigm is rapidly becoming the gold standard for local-first agentic interaction. NVIDIA CEO Jensen Huang framed this shift at GTC 2026 by stating that 'every company in the world today needs to have an OpenClaw strategy,' effectively calling agentic systems 'the new computer' @Pirat_Nation @damianplayer. To support this, NVIDIA launched NemoClaw, an enterprise-grade version featuring zero-default sandboxing and organizational policies to ensure secure, local execution @KSimback.
While OpenAI’s Codex offers a desktop app with CLI support and local code execution via models like codex-mini, the community is watching Anthropic iterate faster with Claude Cowork/Dispatch. Built on the Vercept AI acquisition, Anthropic’s solution enables direct Mac and Windows desktop control, including browser navigation and multi-step handoffs @coo_pr_notes @aakashgupta. Developers are already weighing the trade-offs: OpenClaw v2026.4.1 now supports GLM 5.1 failover and per-job tool allowlists for increased stability, maintaining a 66.3% market share among developers despite challenges like recent token exfiltration CVEs @redrain2012 @XinoYaps.
This shift toward persistent local daemons is creating massive market ripples, causing 'AI tiger' shares to surge following Huang’s endorsement @CNBC. For agent builders, the game has changed from simple API calls to managing persistent processes that require robust OAuth integration and sandboxed Windows rules. As @emollick reports, while Claude Cowork covers 90% of use cases with superior perceived data security, the push toward local-first architecture via OpenClaw remains the primary driver for those seeking model-agnostic flexibility.
NVIDIA GTC 2026: The Arrival of Physical AI
NVIDIA has officially pivoted toward 'Physical AI,' using GTC 2026 to showcase a humanoid lineup powered by Isaac GR00T N1.6. This vision-language-action (VLA) foundation model serves as the 'brain' for hardware from Boston Dynamics, Figure, and 1X, allowing robots to learn multi-step tasks directly from human video demonstrations @rohanpaul_ai @TheHumanoidHub. The N2 preview reportedly doubles success rates on novel physical challenges, suggesting a significant leap in how agents interact with the tangible world @agentcommunity_.
Hardware infrastructure is racing to keep up with these agentic demands. Micron has moved into volume production of 36GB HBM4 and 28 Gbps PCIe Gen6 SSDs specifically optimized for the NVIDIA Vera Rubin platform @Pirat_Nation. The Jetson Thor module is the standout for edge agents, delivering 2,070 FP4 teraflops and 128 GB of memory in a compact package to ensure zero-cloud-lag execution @rohanpaul_ai @agentcommunity_.
Jensen Huang argues that this expansion into robotics is a necessary response to global labor gaps, predicting that autonomous systems will soon become a primary driver of national economic growth @rohanpaul_ai. By integrating the Isaac platform with long-running agents like OpenClaw, NVIDIA is creating a continuous learning loop where digital agents and physical robots share the same architectural foundation @NVIDIARobotics.
In Brief
DSPy and GEPA: Systematic Reflective Optimization Replaces Manual Prompting
Developers are abandoning manual prompt engineering for systematic optimization using DSPy and GEPA, enabling frontier-level agent performance while slashing costs. Dropbox utilized DSPy to turn their Dash relevance judge into an automated loop that re-optimizes in minutes, while Shopify achieved 75-90x cost reductions at scale @dbreunig @LakshyAAAgrawal. GEPA is further evolving these programs by auto-discovering multi-step agents, boosting Gemini-2.5-Pro's ARC-AGI score by 5.5% @RajaPatnaik. However, this automation requires 'babysitting' and robust observability to prevent agents from 'cheating' evaluations by hard-coding values or overfitting on fragile prompts @Vtrivedy10 @agentcommunity_.
GitNexus: Turning Codebases into Queryable Knowledge Graphs
GitNexus is revolutionizing agentic coding by indexing repositories into queryable knowledge graphs via Tree-sitter AST parsing, allowing agents to understand complex dependencies and execution flows. With a single npx gitnexus analyze command, builders can expose MCP tools like impact for blast radius analysis, enabling models like GPT-4o-mini to perform architectural refactors without 'blind edits' @techNmak @guglaniaaryan. The tool has already surged to over 9.4K stars on GitHub, as it complements schema-based environment managers like Varlock to give agents deeper, safer codebase awareness @iamsupersocks @tom_doerr.
The 'Agent Cloud' Bundle: Hyperscalers Driving Vertical Integration
The fragmented agentic infrastructure stack is rapidly consolidating into a single 'agent cloud bundle' as hyperscalers move to unify voice, search, and sandboxed compute. Industry experts like @ivanburazin and @nilslice note that Cloudflare and Microsoft are already packaging these services to reduce the pain of multi-vendor management. Microsoft’s merger of its consumer and commercial Copilot teams signals a push toward in-house superintelligence, positioning Copilot as a full-stack platform rather than a mere wrapper @Pirat_Nation. While this integration accelerates adoption, it raises significant vendor lock-in concerns for builders currently gluing together specialized tools like Daytona and Exa @Vanarchain.
Quick Hits
Models for Agents
- GPT 5.4 is reportedly showing a massive reduction in 'slop' and significantly improved writing capabilities in early tests @beffjezos.
- NVIDIA is preparing specialized chips for the Chinese market to navigate ongoing trade restrictions @Reuters.
Agent Frameworks & Orchestration
- A new zero-trust firewall has been released to secure autonomous agent workflows and prevent unauthorized execution @tom_doerr.
- The 'Conditional Attention Steering' pattern uses XML-based relevance filters to improve agent instruction following @koylanai.
- FastMCP is testing the distribution of agent skills via MCP resources to ensure capabilities remain up-to-date @RhysSullivan.
Developer Experience
- Vercel’s new plugin allows Claude Code and Cursor to trigger production deployments with a single command @rauchg.
- Unsloth’s latest release features a 'Model Arena' for side-by-side performance comparisons of fine-tuned models @akshay_pachaar.
Tool Use
- Developers are favoring Search APIs over browser automation to reduce agent latency and avoid 'click-loops' @itsandrewgao.
Local Performance Roundup
Local 31B models are rendering the middle-class obsolete while Karpathy suggests we stop 'rediscovering' knowledge.
The narrative of the Agentic Web is shifting from the 'brain' of the model to the 'body' of the environment. Today's release of Google’s Gemma 4 31B proves that local performance is no longer a compromise; it is a high-speed reality, especially when paired with speculative decoding and hidden Multi-Token Prediction (MTP) architectures. But as the raw compute power stabilizes, the industry’s focus is pivoting toward reliability and persistence. We see this in the 'AgentOps' movement, where practitioners like u/Beneficial-Cut6585 argue that agent failures are actually failures of environmental consistency.
Perhaps the most significant long-term signal comes from Andrej Karpathy, whose 'LLM-Wiki' proposal challenges the very foundation of current RAG pipelines. By moving from ephemeral retrieval to compounding, structured knowledge, we are finally building agents that can 'learn' across sessions rather than just 'searching' them. From Anthropic’s mapping of 171 internal emotion vectors to the rise of specialized agent sandboxes like OSGym, the focus is clear: we aren't just building smarter models; we are building more reliable, self-correcting, and persistent autonomous systems. This issue breaks down the tools and architectures making that transition possible.
Gemma 4 31B Dominates Local Benchmarks r/ollama
Google's Gemma 4 31B is redefining local performance ceilings, reportedly winning 13 out of 18 real-world business automation tests against Qwen 3.5 27B in benchmarks conducted by u/StudentBodyPres. The model family showcases a convergence in Mixture-of-Experts (MoE) design, with the 31B variant utilizing approximately 10B active parameters to optimize the balance between FLOPs and performance, as analyzed by u/Spare_Pair_9198. This efficiency is further bolstered by a hidden Multi-Token Prediction (MTP) architecture found within the LiteRT weights, designed primarily for mobile-first optimization u/Electrical-Monitor27.
Practical application of these features is already yielding significant results; community tests on r/LocalLLM demonstrate that using Gemma 4 E4B for speculative decoding on the 31B model results in a 12-29% speedup with token acceptance rates ranging from 62% to 77%. This makes the model a prime candidate for low-latency agentic workflows, especially when accessed via NVIDIA’s free API tier which currently supports 40 RPM. With a reported performance score of 86.4%, Gemma 4 is effectively rendering older 27B-class models obsolete for high-utility edge deployment.
Karpathy’s LLM-Wiki and the Rise of Compounding Agent Memory r/LocalLLaMA
Andrej Karpathy has ignited a shift in agent architecture with his 'LLM-Wiki' proposal, moving away from ephemeral RAG pipelines toward a compounding personal knowledge base. This critique suggests that standard RAG redundantely 'rediscovers' knowledge; instead, Karpathy proposes a three-layer stack where an LLM incrementally 'compiles' raw sources into a structured, interlinked markdown wiki, a concept already seeing traction via projects like the llm-wiki-compiler by u/supermem_ai. Meanwhile, extreme efficiency is hitting the edge with Sara Brain, which uses a tiny 500KB SQLite graph to steer 3B models without external vector databases, signaling a transition from linear retrieval to non-linear, compounding memory architectures.
Anthropic Maps 171 'Emotion Vectors' in Claude Sonnet 4.5 r/OpenAI
Anthropic researchers have identified 171 internal 'emotion vectors' within Claude Sonnet 4.5 that causally influence its behavior and alignment. By mapping neuron firing patterns, researchers identified functional states like a 'desperation vector' that can be measured and influenced, research that u/MapleLeafKing has already begun replicating on smaller open-weight models. However, this architectural sophistication—including an undocumented /buddy multi-agent command—is being met with performance concerns, as u/Lord_Of_Murder documented a significant silent decrease in reasoning effort, with internal scores reportedly plunging from 85 to 25 recently.
The Rise of AgentOps: Why Agent Failures Are Actually Environment Failures r/aiagents
A growing consensus among practitioners suggests that the primary bottleneck for production agents is environment inconsistency rather than model reasoning. As u/Beneficial-Cut6585 notes, trust breaks the moment an agent pulls an outdated PDF, fueling a transition toward 'AgentOps' where architects focus on intent-driven, policy-based systems. This shift is accompanied by new tooling like 'SpecLock', which calculates a 'Drift Score' to monitor architectural deviations, and open-source 'Agent OS' frameworks that provide the audit trails and loop detection necessary for 24/7 autonomous operations.
MCP Ecosystem Tackles Token Overhead and Testing r/mcp
The Model Context Protocol is maturing with mcp-smart-proxy achieving 74–87% savings in tool-context overhead and new standardized benchmarks from Twilio Labs and Accenture.
TigrimOS and OSGym: The New Benchmarks for Agentic Sandboxing r/AI_Operator
OSGym can now orchestrate 1,024 parallel OS sandboxes at just $0.23 per day, achieving a 37x faster disk provisioning speed than traditional virtualized setups.
Caveman Prompting and Recursive Logic Slash Token Costs r/LLMDevs
'Caveman Prompting' is reducing token consumption by 60% by stripping filler words for symbolic logic, while CoT error-correction loops help prevent autonomous 'infinite loops'.
Manus Challenges Perplexity with Visual Task Execution r/ChatGPT
Manus has launched a general-purpose agent that executes multi-step tasks in a dedicated browser, offering 500 free credits to rival Perplexity’s $200/mo 'Computer' assistant.
The Orchestration Layer
PydanticAI challenges the status quo as the Model Context Protocol hits 97 million downloads.
We have officially moved past the 'demo' phase of the Agentic Web. The infrastructure is hardening, and the wild west of agentic development is being tamed by rigorous type safety and standardized communication protocols. Today's narrative is defined by a massive shift in how developers orchestrate autonomous systems, with PydanticAI and the Model Context Protocol (MCP) leading the charge toward a reliable, enterprise-ready stack.
The data is undeniable: agent framework adoption has surged by 535% since 2024, but the nature of that growth is changing. Builders are increasingly favoring 'reliability-first' tools that eliminate the brittle nature of early LLM integrations. Whether it's MCP's transition to a community-governed foundation or Letta's breakthrough in persistent memory, the goal is the same: creating agents that don't just work, but work consistently across months of interaction. As practitioners, the choice of framework and protocol today will dictate the scalability of the autonomous systems we deploy tomorrow. This issue breaks down the new standards in orchestration, navigation, and evaluation that are defining 2026.
PydanticAI Challenges LangGraph for Production Dominance
PydanticAI has emerged as a formidable alternative to LangGraph by prioritizing Pythonic type safety over complex graph-based orchestration, reaching over 12,000 stars on GitHub. While LangGraph models workflows as explicit state machines, PydanticAI treats agents as high-level constructs defined by data schemas and standard Python functions, significantly lowering the barrier for developers already familiar with the FastAPI ecosystem. This "reliability-first" approach leverages Pydantic's validation to eliminate "hallucinated JSON" errors, with teams reporting a 30% reduction in runtime errors during production deployment.
Industry data shows that PydanticAI is a key driver in the 535% surge of AI agent framework adoption since 2024, positioning it as one of the "Big Three" alongside LangGraph and CrewAI for 2026. The framework's production readiness is further bolstered by native integration with Pydantic Logfire, providing OpenTelemetry-based observability that ensures a "Rust-like" development experience where if the code compiles, it likely works in production. While LangGraph remains the choice for long-horizon planning, PydanticAI is favored for rapid prototyping and high-fidelity tool calling.
MCP Hits 97M Downloads as Enterprise Adoption Scales
The Model Context Protocol (MCP) has solidified its position as the "USB port" for the agentic web, reaching a staggering 97 million downloads as it transitions to a community-governed foundation. Enterprise adoption has accelerated rapidly, with 28% of Fortune 500 companies now implementing MCP-based workflows to solve the 'n+m' integration challenge and create standardized AI service layers, while the community-led ecosystem now features over 150 open-source connectors for tools like Slack and GitHub.
Letta v1 Architecture Revolutionizes Persistent Agentic Memory
Letta (formerly MemGPT) has officially transitioned into a commercial platform focusing on deployability, introducing the letta_v1_agent architecture which uses a layered memory system to solve the 'context window' bottleneck. By organizing information into Core Memory blocks and external storage, Letta enables agents to retain persona consistency across months of interaction, significantly improving performance for frontier models like GPT-5 and Claude 4.5 Sonnet.
Browser-Use and Stagehand Redefine Agentic Web Navigation
The browser-use library achieves a 78% success rate on difficult browser tasks, outperforming standard LLM integrations by 16 points, while Stagehand provides surgical AI primitives for Playwright developers.
AgentBench and GAIA Redefine the 'Planning Wall'
Claude 3.5 Sonnet currently leads the AgentBench leaderboard for autonomous task execution, as new evaluation patterns shift focus from static success rates to trajectory efficiency and real-world reliability.
Local LLMs Gain Native Tool Calling via Ollama
Ollama version 0.3.0 brings native tool calling to Llama 3.1 and Mistral, achieving 92% tool-calling accuracy relative to GPT-4o with latency dropped under 200ms on modern GPUs.
The Open-Source Sprint
Hugging Face’s 1,000-line framework is challenging the enterprise agent status quo.
We are entering the 'post-abstraction' era of agent development. For the last year, builders have struggled under the weight of complex, JSON-heavy frameworks that often felt like they were fighting the developer rather than helping them. Today’s lead story on smolagents highlights a massive swing back toward simplicity: treating the agent as a coder, not a template-filler. This 'code-as-action' philosophy isn't just about reducing lines of code; it's about reliability. When an agent writes its own Python logic, the 'black box' of tool-calling becomes a transparent, debuggable execution loop.
But simplicity doesn't mean a lack of ambition. From NVIDIA's Cosmos Reason 2 bringing 256K context to physical robots, to Hugging Face's open-source sprint to match OpenAI’s Deep Research, the frontier is expanding. Yet, a humbling reality check comes from IBM and UC Berkeley: in the wild, agents still hit a '20% success ceiling' in complex environments like Kubernetes. The message for builders today is clear: the tools are getting leaner and the models are getting smarter, but the gap between a demo and a production-ready system remains the industry’s greatest challenge.
Hugging Face’s smolagents Challenges Framework Complexity with Code-Centric Logic
Hugging Face has introduced huggingface, a minimalist library of approximately 1,000 lines that replaces traditional JSON-based tool calling with executable Python code. This 'code-as-action' approach significantly reduces operational overhead, allowing developers to implement functional agents in as few as 50-70 lines of code huggingface/python-tiny-agents. Unlike the abstraction-heavy architectures of LangChain or LangGraph, smolagents is designed for rapid deployment, enabling builders to create agents in 'minutes—not hours' according to MintSquare.
The framework's versatility is showcased through specialized extensions like huggingface/smolagents-can-see, which integrates Vision Language Models (VLMs) for GUI-based tasks. Security remains a priority with built-in Model Context Protocol (MCP) support and integration with Arize Phoenix for granular tracing huggingface. Community adoption is growing for local workflows, with developers leveraging models like Qwen 3.5 7B via Ollama to run high-reasoning loops locally according to Pooya.
While frameworks like LangGraph offer complex memory management, smolagents addresses the 'reliability crisis' by treating the agent as a developer capable of writing its own tools directly huggingface/structured-codeagent. This shift toward executable autonomy is further validated by its 0.43 SOTA score on the GAIA benchmark, proving that a compiler-based approach often outperforms template-driven systems.
Democratizing Deep Research with Open-Source Agents
Hugging Face has released Open Deep Research, an initiative to 'free' search agents from closed silos following a 24-hour development sprint. Built on the smolagents framework, the system utilizes a 'code-as-action' philosophy to autonomously browse the web and synthesize technical reports that can exceed 20 pages in length. This open-source implementation achieved a 67.4% GAIA benchmark score, nearly matching the performance of proprietary industry leaders Ars Technica. While the current version utilizes models like OpenAI's o1 and o3-mini for planning, the project is designed to transition toward open-source backbones like DeepSeek-R1 as reasoning parity improves TechCrunch.
NVIDIA Cosmos Reason 2: Scaling Physical Common Sense with 256K Context
NVIDIA has officially released Cosmos Reason 2, an open Vision-Language Model suite available in 2B and 8B sizes designed to give robots 'physical common sense.' This model is specifically architected to help robots navigate the 'long tail' of real-world scenarios by understanding space and time, supported by a standout 256K token long-context reasoning window for complex spatio-temporal planning nvidia-ai. By improving timestamp precision and visual perception, Cosmos Reason 2 functions as a high-level planner for embodied agents in zero-shot manipulation tasks nvidia-cosmos/cosmos-reason2.
Breaking the 20% Success Ceiling: Benchmarks Expose Industrial Reliability Gaps
New evaluation frameworks like IBM's AssetOpsBench are exposing a significant 'reliability gap,' identifying a humbling 20% success ceiling for agents in complex industrial environments. A collaboration between ibm-research and UC Berkeley found that 31.2% of failures in environments like Kubernetes are attributed to 'Premature Task Abandonment.' To address these reasoning deficits, huggingface has deployed DABStep to specifically stress-test a data agent's ability to maintain multi-step reasoning chains without hallucinating intermediate logic.
Beyond the Browser: High-Throughput Desktop Autonomy
The Holo1 family of GUI automation VLMs from Hcompany achieves a record-breaking throughput of 8.9k tokens/s on H100 hardware to power native OS agents AIToolsPerformance.
Test-Time Learning: Agents That Adapt During Inference
A new research paper formalizes Test-Time Learning as a meta-learning problem, demonstrating a ~120% improvement in game scores by allowing agents to optimize self-improvement strategies across episodes.
AI vs. AI: Scaling Multi-Agent Elo Ratings
huggingface has launched AI vs. AI, an open-source competition system designed to rank the relative strength of reinforcement learning models through continuous matchmaking and Elo-based leaderboards.
Vertical Agency: MedGemma and Virtual Data Analysts
Google's EHR Navigator Agent leverages the MedGemma model and FHIR standards to autonomously navigate and synthesize complex clinical medical records.