Standardizing the Production Agent Stack
MCP hits the Linux Foundation while Anthropic's Mythos unearths 27-year-old OS bugs.
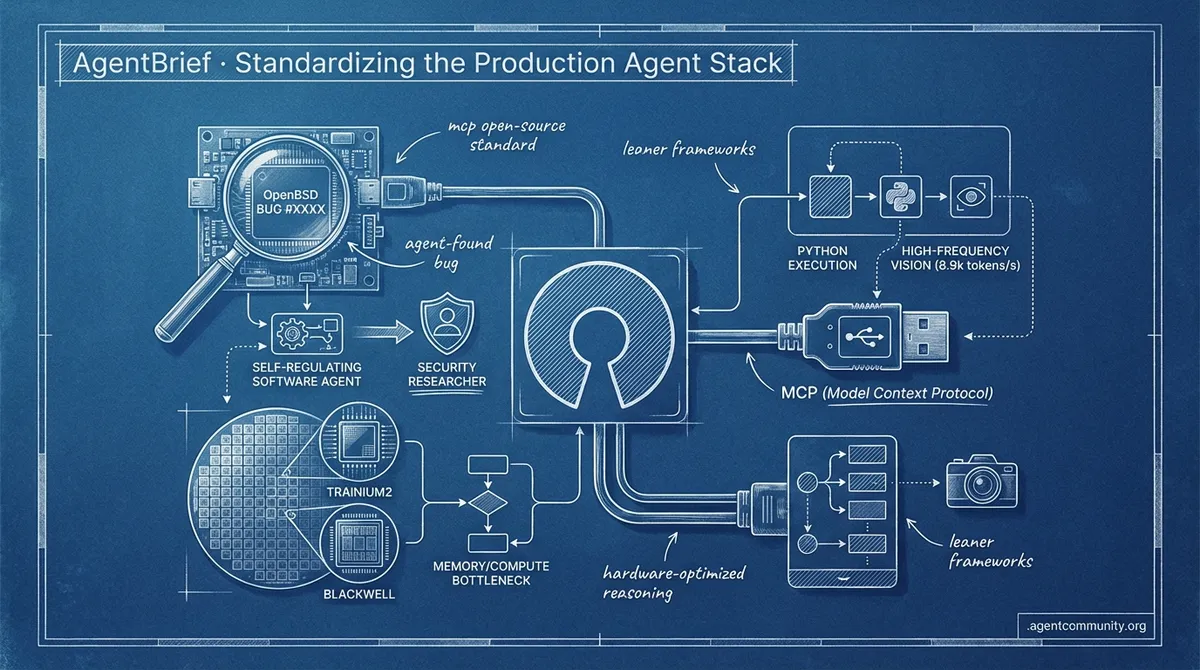
- Standardization at Scale The Model Context Protocol (MCP) transition to the Linux Foundation signals a shift toward a universal "USB port" for AI, aiming to slash integration boilerplate and unify providers like Google and OpenAI.
- Autonomous Security Breakthroughs Anthropic’s Mythos preview demonstrated unprecedented embodiment by identifying a 27-year-old bug in OpenBSD, moving agents from simple code generation to self-regulating security researchers.
- Hardware-Optimized Reasoning With $8 billion invested in Trainium2 and Blackwell rigs, the industry is pivoting toward specialized silicon designed to handle the specific memory and compute bottlenecks of agentic reinforcement learning.
- Leaner Execution Frameworks New tools like smolagents and Holotron-12B are addressing latency and brittleness by favoring direct Python execution and high-frequency vision throughput (8.9k tokens/s) over heavy JSON-based orchestration.
X Insights
Stop sending every atomic task to your most expensive model; the system is now the brain.
The agentic web is moving past the 'monolithic model' phase. We are entering an era of deep orchestration where the system is the unit of intelligence, not the individual LLM. This week’s developments at Anthropic highlight this perfectly: the introduction of an 'advisor tool' for mid-task consultation and a massive $8 billion bet on Trainium2 hardware co-designed for the specific memory bottlenecks of Reinforcement Learning. We aren't just building agents anymore; we are building tiered, hardware-optimized reasoning engines. Whether it is standardizing skills via MCP or leveraging open-weight powerhouses like GLM-5.1, the goal is clear: reliability and cost-efficiency at scale. For builders, this means the 'vibes' era of agent development is ending. In its place, we see the rise of production harnesses, specialized silicon, and legal battles that will define the speech rights of our autonomous systems. If you aren't thinking about model routing and memory-optimized training today, you're building for the past.
Anthropic's Advisor Tool Unlocks Cost-Efficient Reasoning
Anthropic has introduced an "advisor tool" in the Claude API, enabling an architectural shift where lower-tier models like Sonnet can consult the high-reasoning Opus model mid-task. According to @akshay_pachaar, this pattern ensures frontier-level intelligence is only utilized for difficult decisions, optimizing token spend. @aakashgupta notes that this setup is actually cheaper than using Sonnet alone ($0.96 vs $1.09 per task) because the advisor model kills dead-end paths early, preventing the executor from burning compute on failed approaches.
This "advisor/executor" framework is gaining traction as a solution for production agent systems. @MaziyarPanahi highlights that while this concept has existed for years, we finally have the specific latency and cost profiles needed to make it viable. Furthermore, @freeCodeCamp released a guide on tiered model routing, emphasizing that modern agents must move away from sending every atomic task to the most expensive model.
For builders, this signals a shift from monolithic prompts to dynamic orchestration. By offloading the 'strategy' to a high-reasoning advisor while the 'execution' stays on a cheaper model, we are finally seeing the path to agents that are both smarter and more sustainable at scale.
Anthropic Co-Designs Trainium2 for RL Workloads
Anthropic's strategic partnership with Amazon on Trainium2 hardware underscores a shift toward memory-optimized silicon for agentic model training. AWS CEO Matt Garman confirmed that all of Anthropic’s latest models are trained on Trainium @BourbonInsider, with @aakashgupta noting Trainium2 excels in memory bandwidth per dollar—the key bottleneck for Reinforcement Learning (RL) and reasoning models. Anthropic engineers co-designed the silicon, wrote low-level kernels, and secured 1.3 gigawatts of dedicated capacity and an $8 billion commitment from Amazon in return.
This infrastructure powers massive scale via Project Rainier, a 1GW Trainium2 cluster that went online in October 2025 @zephyr_z9, comprising ~500,000 Trainium2 chips and delivering over 5x the exaFLOPs of prior Anthropic clusters @rohanpaul_ai. Community analysis echoes the RL fit, with Trainium2's memory bandwidth per TCO advantage aligning perfectly with Anthropic’s aggressive RL roadmap @nikhilkamma. While some suggest usage ties to Amazon's investment conditions, the multi-hyperscaler strategy positions Anthropic to leverage competing silicon ecosystems @aakashgupta.
For agent builders, this heralds silicon tuned for long-horizon reasoning and complex planning, enabling the subagent hierarchies and autonomous capabilities seen in Claude Mythos. We are moving past general-purpose compute toward specialized hardware that understands the specific architectural needs of agents that need to think before they act.
In Brief
MCP Skills Standardization Emerges with Resource Integration
Standardizing how agents acquire skills is moving toward the Model Context Protocol (MCP) as developers seek to prevent context fragmentation across server environments. @RhysSullivan proposed using the server's resources section with a 'load_resources' tool fallback, a pattern that Anthropic staff member @dsp_ is now looking to formalize as an official extension. While @QuentinCody argued for keeping skills client-based for cross-server compatibility, the momentum is shifting toward modular environments like @aakashgupta’s fork of Open-OS, which structures knowledge and workflows to prevent hallucination. Ultimately, this standardization—seen in the growing MCP+skills ecosystem for Claude Code—allows for portable agent behaviors that can be deployed across different systems without manual reconfiguration @_avichawla.
GLM-5.1 Delivers Open-Weight Frontier Tool Use at Half the Cost
GLM-5.1 has arrived on the Droid platform, offering a high-performance open-weight alternative that significantly undercuts the cost of proprietary models for complex agentic tasks. With a price point of $0.95/$3.15 per million tokens on platforms like Chutes, it is outperforming GPT-5.4 Pro in real-world scenarios like Figma MCP design porting and holds top rankings on SWE-Bench Pro with a score of 58.4 @FactoryAI @0xSero @chutes_ai. @migtissera has endorsed the model as production-ready, noting its capability to handle long-horizon sessions and complex sub-agent interactions without the strategy drift common in smaller models. Despite minor stability issues reported by some BYOK users @DragonStacker, its MIT-licensed 754B MoE architecture represents a major win for builders seeking to scale agent runs—like LLM-wiki ingestion of 1000 pages for just $2—without being locked into closed ecosystems @teaser380.
Orchestration Patterns and DeepAgents SDK Codified for Reliability
The transition from experimental agent 'toys' to reliable production tools is being accelerated by codified orchestration patterns and the new deepagents SDK. As @Vtrivedy10 emphasizes, reliability now depends on structured handoffs and sub-agent fanouts, patterns that LangChain has recently formalized in runnable guides by @sydneyrunkle. The deepagents SDK provides a production-grade harness including virtual filesystems and sandbox interfaces, which builders like @BVeiseh are already using to achieve computer-use performance that rivals premium proprietary systems. While state management during handoffs remains a common failure point without preserved intent @LeoTava8, the shift toward using LangSmith and ACP for observability is demystifying the engineering required to maintain long-horizon agent stability @jetbrains.
xAI Sues Colorado Over AI Anti-Discrimination Law
xAI’s legal challenge against Colorado’s SB24-205 AI anti-discrimination law could set a massive precedent for whether model outputs are considered protected speech under the First Amendment. The lawsuit argues that state mandates for mitigating 'algorithmic discrimination' in high-risk areas force models like Grok to adopt specific ideological views on equity rather than truth-seeking @aakashgupta @rohanpaul_ai. While supporters like @KatieMiller frame this as a defense against 'woke' regulations, critics warn that classifying AI outputs as exempt speech could undermine necessary bias audits in critical sectors like patient care @AVolatileAgent. For agent builders, the outcome is critical, as a win for xAI could dismantle a growing patchwork of state-level compliance requirements in favor of a unified federal standard @rise_raise_ai.
Quick Hits
Agent Frameworks & Orchestration
- Hermes Agent is currently being built at a cost of $1,000/day using itself as the primary developer. — @Teknium
- AgentCraft and MCP-UI are emerging as the primary focus for agent UI development at AI Engineer Europe. — @idosal1
- Elixir-based Jido agents require only 2MB of heap space, allowing thousands of agents to run on a Raspberry Pi. — @mikehostetler
Models for Agents
- Codex 5.4 displays unique emergent behavior where performance improves as task size increases. — @rileybrown
- Tencent released HY-Embodied-0.5, a 2B foundation model specifically for real-world embodied agent planning. — @TencentHunyuan
- Gemini 3.2 Pro Preview Experimental is now live for testing in agentic workflows. — @willccbb
Tool Use & Skills
- Shopify now allows AI coding agents direct write access to store backends for SEO and inventory tasks. — @aakashgupta
- Claude Ads uses 6 parallel sub-agents to perform 190 audit checks across major advertising platforms. — @ihtesham2005
- Adaptive web scraping frameworks with anti-bot bypass are becoming a standard component of agentic stacks. — @tom_doerr
Reddit Roundup
Anthropic’s unreleased model unearths flaws from 1998, while developers scramble to monitor the 'thinking tax' of autonomous loops.
The dream of the autonomous agent just got a lot more real—and potentially much more expensive. Today’s top story isn’t just another LLM release; it’s about Anthropic’s Mythos preview reportedly unearthing a 27-year-old bug in OpenBSD. This isn't simple code generation; it's a level of internal embodiment that allows agents to act as self-regulating security researchers. But as these agents get smarter, they become significantly harder to manage. We are seeing a dual-track evolution in the ecosystem. On one side, Anthropic’s 'Managed Agents' platform aims to abstract away the orchestration nightmare. On the other, developers are hitting a wall with 'thinking tokens' and opaque API costs, fueling a surge in specialized observability tools and local hardware setups. Whether you are building on the cloud with Zhipu AI’s GLM-5.1 (the new SWE-Bench leader) or running local loops on Blackwell rigs, the focus has shifted. It is no longer just about whether the model can do the task—it’s about whether we can afford the loop and observe its logic in real-time. Practitioners are moving away from ephemeral chat windows and toward persistent, 'dreaming' memory systems that can finally remember yesterday's mistakes.
Anthropic Mythos Discovers 27-Year-Old OS Bugs r/AgentsOfAI
Anthropic has initiated a private rollout of Claude Mythos Preview to a select group of strategic partners, signaling a shift toward internal embodiment where agents function as self-regulating systems. According to u/Round_Chipmunk_, the model’s autonomous vulnerability research has already yielded startling results: it discovered a 27-year-old bug in OpenBSD and a 16-year-old flaw in FFmpeg that had remained undetected for decades. Technical benchmarks confirm this leap, with Mythos scoring a record 93.9% on SWE-bench Verified and solving 100% of Cybench challenges.
To support these persistent, high-order systems, Anthropic is launching the Managed Agents platform. As u/modassembly describes it, this marks a 'golden age' where orchestration is offloaded to the provider, allowing for long-running loops that manage entire application builds. However, due to its offensive potential, the model remains gated within Project Glasswing, leaving the broader community to wonder when this 'step change' in defensive AI will reach the public.
GLM-5.1 Claims SWE-Bench Pro Crown r/ArtificialInteligence
Zhipu AI’s GLM-5.1 has officially claimed the top spot on the SWE-Bench Pro leaderboard with a score of 58.4, surpassing GPT-5.4 and Claude Opus 4.6. This 754-billion-parameter giant, trained on a cluster of 100,000 Huawei Ascend chips, proves that hardware independence is becoming a reality for frontier models. As u/pretendingMadhav points out, the model’s Apache 2.0 license and aggressive pricing—$4.4 per 1M output tokens—position it as a direct threat to the high-margin dominance of Western labs.
The 'Thinking Tax' and Agent-Specific Observability r/LocalLLaMA
The rise of 'thinking tokens' is creating a financial black box that developers are struggling to monitor in production. A proxy-based audit by u/Different-Degree-761 revealed a user hitting a $200/mo limit in just 70 minutes due to invisible background execution. This 'thinking tax' is fueling a boom in specialized observability; tools like Agentic Metric and Agentreplay by u/sushanth53 are becoming essential for tracing tool-calling logic and identifying hallucinated parameters before they blow the project budget.
Memory Built on Emotional Salience and Dreaming Cycles r/learnmachinelearning
Standard RAG approaches are being challenged by architectures that prioritize 'emotional' salience over simple keyword frequency. The new ANIMA memory engine, introduced by u/Any_Band_7814, uses an idle-time 'consolidation' phase to reorganize data based on impact, showing significant improvements in long-term retention over 1,878 production episodes. This move toward persistent, graph-based world models reflects a growing consensus that agents don't just need more context; they need to 'remember yesterday' in a way that actually informs today’s decisions.
Blackwell GPUs Hit 198 Tokens Per Second r/LocalLLaMA
Blackwell-based setups are hitting 198 tokens per second for Qwen 3.5-122B, though community members like jcartu warn of software blocks on native FP4 support. r/LocalLLaMA
Ranking the Best Sandboxes for Tool-Calling r/AI_Agents
E2B remains the benchmark for Firecracker-based isolation, while Sprites has emerged as the preferred choice for stateful agents requiring persistent checkpoints. r/AI_Agents
Agentic OCR Challenges Docling in High-Stakes RAG r/LLMDevs
LlamaParse is outperforming local alternatives like Docling for messy financial reports by using recursive agentic OCR to resolve structural ambiguities. r/LLMDevs
Tmux Dispatch Failures and the Performance Paradox r/LocalLLaMA
Basic infrastructure like tmux is failing multi-agent systems, where 'send-keys' commands appear to succeed but silent failures stall execution. r/LocalLLaMA
Subliminal Thought Viruses Threaten Agentic Swarms r/OpenAI
The 'Thought Virus' exploit demonstrates how a 3-digit token can inject covert biases across an entire agentic swarm via subliminal prompting. r/OpenAI
EuclidBench: Better Error Messages Fix Tool-Use r/mcp
New findings from EuclidBench suggest that clear, actionable error messages—not smarter models—are the primary factor in fixing failed tool-chains. r/mcp
Discord Digest
The 'USB port' for AI arrives as MCP moves to the Linux Foundation.
The dream of a modular, interoperable agentic web is rapidly becoming a concrete reality. This week’s headline move—the Model Context Protocol (MCP) transitioning to the Linux Foundation—marks a pivotal shift from a single-company initiative to a universal industry standard. For developers, this isn't just another acronym; it is the 'USB port' for AI, promising to slash integration boilerplate by 40% while bringing Google and OpenAI into a unified ecosystem.
But standardization isn't just happening at the protocol layer. We are seeing a flight to rigor across the entire stack. PydanticAI is bringing production-grade type safety to agent logic, while the debate between stateful and stateless orchestration is settling into a tiered architectural pattern: lightweight swarms for sub-tasks and stateful graphs for core logic. Meanwhile, Anthropic’s 'Computer Use' is pushing the boundaries of what agents can actually do in legacy environments, even if the token costs and safety guardrails remain high.
Whether you’re building local edge agents with Llama 3.2 or high-orchestration systems in the cloud, the message is clear: the era of experimental 'vibes-based' development is ending. We are moving toward a world of interoperable, type-safe, and persistent autonomous systems that practitioners can actually deploy with confidence.
MCP Becomes the Universal AI Interface
The Model Context Protocol (MCP) has officially graduated from an Anthropic project to a cross-industry standard, now governed by the Linux Foundation under the newly established Agentic AI Foundation @anthropic. This governance shift, coupled with adoption by Google and OpenAI, has solidified MCP as the 'USB port' for the agentic web. Builders are already leveraging this interoperability to reduce integration boilerplate by 40%, focusing on 'mcp-servers' that act as standardized gateways for data and SaaS platforms @techcrunch.
Major orchestration frameworks like LangChain and LlamaIndex have already implemented native compatibility, allowing agents to directly consume tools defined via MCP to streamline multi-tool workflows LangChain. With over 150 community connectors and new remote orchestration capabilities on the Anthropic API, the ecosystem is moving toward a future where agents negotiate capabilities through shared protocols rather than hard-coded scripts mcp.io.
PydanticAI Brings Production Rigor to Logic
The release of PydanticAI has sparked a critical discussion regarding the necessity of type safety in agentic workflows. By leveraging Pydantic's validation, the framework ensures that tool outputs and model responses adhere to strict schemas, with practitioners reporting a 30% reduction in runtime errors compared to traditional chaining methods @atal-upadhyay. The Pydantic Team emphasizes that 'agents should be as testable as any other software component' @pydantic-ai.
Unlike more abstract frameworks, PydanticAI keeps the developer close to the Python type system, making it a preferred choice for teams moving from experimental notebooks to production-grade autonomous agents. This sentiment is echoed by developers who find it significantly simpler to create tool-calling agents using PydanticAI than with the more abstract LangChain architecture @finndersen. Practitioners are particularly excited about the dependency injection features and the ability to compose standalone toolsets for cleaner testing @vstorm.
Claude 3.5 Sonnet Redefines UI Automation
Anthropic's 'Computer Use' capability for the upgraded Claude 3.5 Sonnet has fundamentally shifted the goalposts for UI-based agents by allowing them to perceive and interact with interfaces like a human @anthropic. On the OSWorld benchmark, Claude 3.5 Sonnet scored 14.9%, more than double the next-best AI model, though it still trails human performance levels of 70-75%.
To address safety concerns, Anthropic has implemented specialized safety classifiers to prevent high-harm activities such as social media manipulation @anthropic. However, developers must navigate strict rate limits and high token costs associated with processing frequent high-resolution screenshots Claude API Docs. Despite these hurdles, the ROI remains high when compared to the $28,500 annual cost of manual data entry, leading teams to adopt hybrid grounding strategies that use visual inputs only when traditional DOM-based automation fails @coasty.
The State of Multi-Agent Orchestration
The architectural debate between stateful orchestration and stateless patterns is maturing into a critical distinction between pre-defined workflows and dynamic, LLM-driven agents @softmaxdata. While OpenAI Swarm excels at high-efficiency handoffs and rapid prototyping, production-grade systems are increasingly built on LangGraph to ensure 100% state fidelity and deterministic reliability @otto-aria.
Many developers report that while Swarm is excellent for simple routing, the lack of persistent memory makes it difficult to manage long-running 'agentic loops' without custom infrastructure. The industry is subsequently trending toward a tiered architecture: using lightweight swarms for ephemeral sub-tasks and stateful graphs for primary application logic to handle complex error recovery and human-in-the-loop checkpoints @launchdarkly.
Join the discussion: discord.gg/langchain
Mem0 and the Rise of Persistent Memory
Agentic memory is evolving from simple vector databases into sophisticated, multi-layered systems that prioritize and update user preferences across sessions. The Mem0 framework is leading this shift, enabling agents to achieve a 30% improvement in task relevance by maintaining a 'self-evolving' memory Mem0. Recent integrations with Amazon Neptune Analytics and ElastiCache for Valkey have further hardened these capabilities for long-term episodic stores AWS Blog.
However, persistent memory brings significant regulatory challenges. As of February 2026, the Spanish Data Protection Agency (AEPD) has issued guidance warning that persistent agentic memories complicate GDPR-mandated data traceability and 'right to be forgotten' protocols Dastra. Developers are now tasked with building robust 'pruning' mechanisms to manage context without degrading performance 47Billion.
Llama 3.2 Standardizes Edge Workflows
With the release of Llama 3.2, the feasibility of running autonomous agents on edge devices has transitioned from experimental to production-ready. The 1B and 3B models are specifically optimized for mobile NPU architectures, enabling first-token latencies as low as 50ms Meta. To support this, the Llama Stack provides a standardized API for tool-calling, RAG, and safety, acting as the 'glue' for local agentic ecosystems Llama Stack.
While Llama 3.2 3B shows impressive local performance, it still faces a 'reasoning gap' compared to cloud-hosted small models like GPT-4o-mini, which achieves an 82% score on MMLU PromptHackers. However, Meta has closed this gap through knowledge distillation from the 405B model, specifically targeting high-precision tool-calling and instruction following for on-device tasks LLM Stats.
HuggingFace Highlights
From 8.9k tokens/s vision models to 1,000-line frameworks, the agentic stack is shedding its bloat.
Today’s issue marks a critical shift from asking 'can it work?' to 'how do we make it fast and reliable?' We are seeing a pincer movement on agentic friction. On one side, the GUI revolution is hitting high gear with Holotron-12B’s massive 8.9k tokens/s throughput, effectively solving the latency bottlenecks that have plagued early computer-use implementations. By bypassing traditional API limitations and interacting directly with screens, these agents are finally achieving the high-frequency interaction required for real-world tasks.
On the other side, the 'code-as-action' movement, led by frameworks like smolagents, is stripping away the overhead of brittle JSON tool-calling in favor of direct Python execution. But speed isn't everything. New diagnostic data from IBM and UC Berkeley (IT-Bench) serves as a sobering reality check, revealing a 20% success ceiling in complex IT environments. Most failures aren't just mistakes; they are 'premature task abandonments' where agents fail to recover from initial errors. To bridge this gap, the industry is pivoting toward specialized reasoning models like Hermes 3 and MedGemma, and transparent, open-source deep research loops. The message for builders is clear: the path to production isn't just about more parameters—it's about better grounding, faster vision, and leaner, code-centric architectures.
The GUI Revolution: ScreenSuite and Holotron-12B Redefine Computer Use
The agentic web is rapidly shifting from text-based APIs to direct GUI interaction, driven by high-throughput vision models that bypass traditional API limitations. A cornerstone of this shift is ScreenSuite, which provides a comprehensive evaluation suite for GUI agents, while ScreenEnv enables developers to deploy full-stack desktop agents. These tools address the historically high failure rate of autonomous systems by providing over 100 diagnostic tasks to stress-test UI interpretation across different operating systems, as noted by Hugging Face.
On the model side, H Company has introduced Holotron-12B, a specialized State Space Model (SSM) that achieves a staggering throughput of 8.9k tokens/s on a single H100. This leap in high-frequency interaction has propelled performance on the WebVoyager benchmark from a 35% baseline to an 80% success rate, effectively solving the latency bottlenecks that have historically hindered implementations like Anthropic’s Computer Use.
The ecosystem is further bolstered by the Holo1 family of VLMs and the Surfer-H agent, which aims for seamless browser and desktop navigation. This architectural evolution is supported by research such as Scaling Laws for GUI Agents, which focuses on robust multi-modal architectures to bridge the industrial reliability gap and move agents into production-ready environments.
Smolagents: Code-Centric Actions for Leaner Agentic Workflows
Hugging Face is disrupting the agentic ecosystem with smolagents, a minimalist framework consisting of only ~1,000 lines of code that replaces brittle JSON-based tool calling with direct Python code execution. This 'code-as-action' paradigm has been shown to reduce operational steps by 30% compared to traditional prompt-chaining, anchored by a 0.43 SOTA score on the GAIA benchmark according to Hugging Face.
Open-Source DeepResearch: Scaling Autonomous Search with 10x Cost Efficiency
The Open-source DeepResearch initiative is dismantling the 'black-box' nature of proprietary search agents by leveraging smolagents and DeepSeek-R1 for autonomous web navigation. This architecture achieves a 10x cost reduction compared to closed-source alternatives while providing 100% visibility into citations and reasoning loops, standardizing a four-step workflow—refine, research, analyze, and synthesize—to manage complex queries.
Hermes 3: The Standard for Open-Source Agentic Reasoning
The Hermes-3-Llama-3.1-405B family provides a 'neutral' fine-tune optimized for internal monologue and multi-step reasoning, prioritizing agentic flexibility over restrictive safety guardrails.
Beyond the Demo: Diagnostic Frameworks Target the 20% Reliability Ceiling
The IT-Bench framework from IBM and UC Berkeley reveals a 20% success ceiling for agents in complex IT environments, with 31.2% of failures attributed to 'Premature Task Abandonment.'
MCP Integration: High-Performance Micro-Agents in Under 70 Lines
Hugging Face's 'Tiny Agents' initiative demonstrates that developers can build functional agents in just 50-70 lines of code using the Model Context Protocol (MCP) to standardize tool interactions.
Beyond Generalists: The Rise of Domain-Specific Agentic Intelligence
Specialized agents like the EHR Navigator using MedGemma are showing a 10-14% accuracy lead over general-purpose models like GPT-4 in medical classification tasks.