Hardening the Agentic Production Stack
As trillion-parameter models hit the web, practitioners are ditching complex abstractions for minimalist code and rigorous state management.
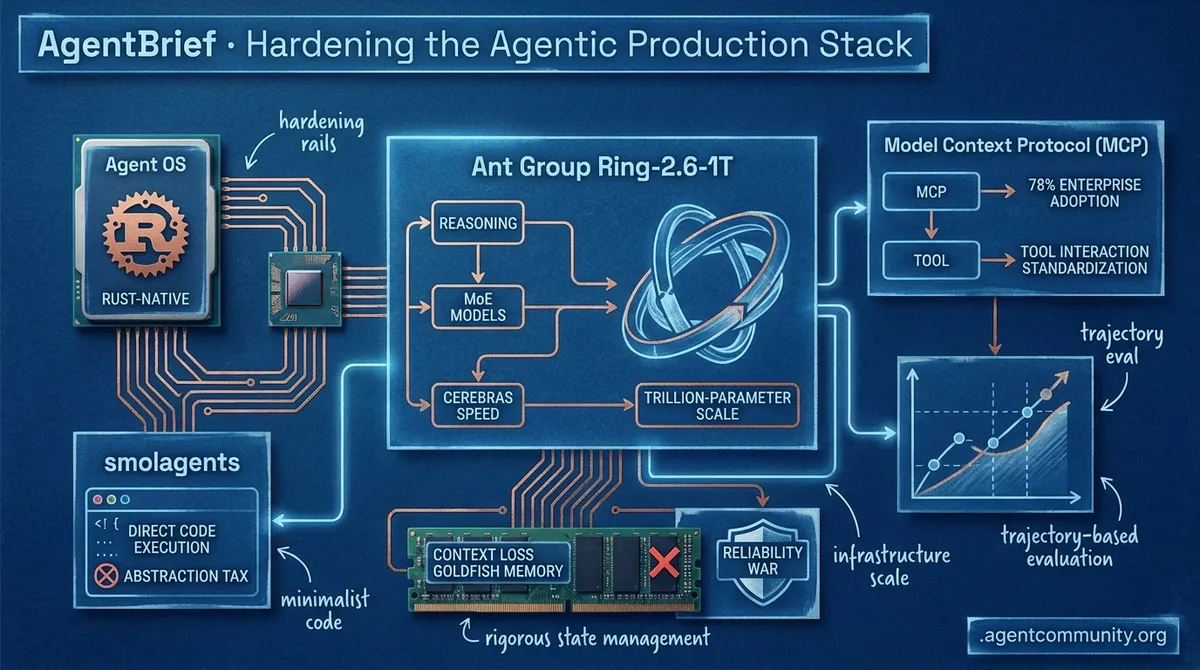
- Hardening Production Rails Enterprise agent projects face a predicted 40% failure rate due to context loss and 'goldfish memory,' driving a shift toward 'Agent OS' architectures and Rust-native performance.
- Minimalism vs. Complexity New frameworks like 'smolagents' are ditching the 'abstraction tax' for direct code execution, achieving 67% success on GAIA benchmarks by cutting through brittle JSON schemas.
- The Reliability War Browser-based agents are moving toward trajectory-based evaluation as the Model Context Protocol (MCP) hits 78% enterprise adoption, standardizing how agents interact with tools.
- Trillion-Parameter Reasoning Infrastructure is scaling to meet autonomous demands, with Ant Group's massive MoE models and Cerebras’ inference speed redefining the performance ceiling for the agentic web.
with our friends at CraftHub
Craft Conference — June 4–5, 2026, Budapest — Two days of software craft talks at the Hungarian Railway Museum. Community discount included.
Get the discount →
X Pulse
Trillion-parameter reasoning hits the open web while your phone becomes an agent dashboard.
We are moving past the 'chatbot' era into the era of the high-bandwidth agentic web. This week’s news cycle underscores a massive shift: the infrastructure is finally catching up to our autonomous ambitions. From Ant Group’s open-sourcing of a trillion-parameter MoE model specifically designed for agentic reasoning to Cerebras proving that the market will pay a premium for wafer-scale inference speed, the message is clear—latency and reasoning depth are the new battlegrounds. As builders, we’re no longer just tweaking prompts; we’re orchestrating complex workflows across an emerging 'Agent Cloud.' Whether it’s OpenAI enabling mobile 'vibecoding' for remote execution or the heated debate over Anthropic’s stance on closed weights, the friction between centralized safety and open innovation is reaching a boiling point. The tools are getting faster, the models are getting deeper, and the ability to control these systems from a mobile dashboard signals a shift toward agents as a background utility rather than a foreground interaction. If you aren't building for long-horizon execution now, you're already behind.
Ant Group Open-Sources Ring-2.6-1T: Trillion-Parameter Reasoning for Agents
Ant Group’s InclusionAI has dropped a massive open-source gift for agent builders: Ring-2.6-1T. This 1-trillion-parameter Mixture-of-Experts (MoE) model, featuring 63B active parameters under an MIT license, is purpose-built for production agent workflows and long-horizon tasks @AntLingAGI. Its standout feature is 'Adjustable Reasoning Effort', allowing developers to toggle between 'high' mode for cost-efficient multi-step execution and 'xhigh' for deep research and complex logic @hasantoxr.
The community is already benchmarking the model against real-world agent tasks rather than just 'benchmark theater.' In its 'high' mode, Ring-2.6-1T hit SOTA marks with 87.60 on PinchBench and 74.00 on SWE-Bench Verified, while 'xhigh' mode achieved a staggering 95.83 on AIME 26 @AntLingAGI. Early testers like @mylifcc and @alphabatcher report stable task decomposition and tool collaboration when integrated with frameworks like Claude Code.
For those of us shipping agents, this model represents a shift toward 'inference-time compute' optimization. By using the IcePop algorithm for stable training at a trillion-scale, Ant Group is providing a foundation that is compatible with major agentic tools like OpenClaw and Kilo Code @hasantoxr. The availability on Hugging Face means we finally have a viable open-weight alternative for the most demanding autonomous pipelines @hasantoxr.
OpenAI Launches Codex Mobile: Your Phone is Now an Agent Dashboard
OpenAI is bringing 'vibecoding' to the pocket with the release of Codex in the ChatGPT mobile app. Builders can now review outputs, steer execution, and approve next steps directly from iOS or Android while the actual compute runs on a remote devbox or Mac @OpenAI. This setup uses a 'Chats First' approach combined with voice mode to allow for intuitive, remote computer control @rileybrown.
The developer community has been quick to experiment with the mobile-to-desktop bridge. Integrations like Vercel 'Yolo Mode' are already enabling rapid deploys from the sidewalk, though some like @steipete have warned about high token burn when agents run in autonomous issue-to-fix loops. To overcome native Mac limitations, third-party tools like Tailscale are being used to connect mobile devices to Windows or Linux environments via Orca @JinjingLiang.
While some harbor concerns about mobile latency for production oversight, the consensus is that this shifts the developer's role toward a high-level 'dashboard' supervisor @MoeSbaiti. With full access to desktop plugins via @ mentions and all standard commands through the slash menu, the barrier between 'thinking of a fix' and 'executing a fix' has effectively vanished @Dimillian.
In Brief
The Rise of the Specialized 'Agent Cloud'
The industry is rapidly pivoting toward a 'Dedicated Agent Cloud' designed to handle the bursty, stateful demands of autonomous workloads. Experts like @ivanburazin argue that we need consumption-based APIs—similar to Stripe's model—that bundle primitives like sandboxes and web search to manage unpredictable spikes. Cloudflare is currently positioned as a frontrunner with its Workers and new Sandbox GA, though builders like @rauchg note that 59% of Vercel AI Gateway tokens already come from agentic tool calls. While the shift promises easier scaling, critics like @alienorg warn of billing traps and the urgent need for better identity controls to prevent agents from running amok.
Open-Weight Backlash Against Anthropic’s Policy Paper
Anthropic’s latest policy paper on AI leadership has ignited a firestorm within the open-weight community over its advocacy for centralized control. The report, '2028: Two Scenarios for Global AI Leadership,' suggests that keeping frontier systems closed is essential to prevent global adversaries from weaponizing AI for cyber ops @AnthropicAI. This stance has drawn sharp rebukes from developers like @MatthewBerman, who calls it a move toward regulatory capture, and @BrianRoemmele, who argues that gatekeeping actually hands the advantage to China’s rapidly iterating open-weight ecosystem. While some defend the closed model for mitigating CBRN risks @InfiniteHexx, the consensus among builders like @Dan_Jeffries1 is that wide distribution remains the best defense.
Cerebras IPO Validates Wafer-Scale Agent Compute
Cerebras Systems ($CBRS) made a massive market debut, validating the demand for wafer-scale hardware capable of supporting high-speed agentic inference. The stock surged over 90% to a $66B valuation, driven by the WSE-3 chip's ability to deliver 21 PB/s on-chip bandwidth—orders of magnitude faster than traditional GPUs @SemiAnalysis_ @bookwormengr. For agent builders, this translates to interactive performance like 1000 tokens/second for coding tasks, a critical threshold for ambient AI agents @sohan_ono. Despite risks associated with customer concentration, the $20B+ deal with OpenAI suggests that the future of agents will be powered by hardware that treats latency as a first-class citizen @theinformation.
Quick Hits
Agent Frameworks & Orchestration
- Dify is hosting a live webinar on building and embedding context-aware AI chatbots @dify_ai.
- The Conductor build tool is emerging as a centralized orchestration layer for complex agent workloads @latentspacepod.
- Camel-AI now supports OrcaRouter integration for more flexible framework routing @CamelAIOrg.
Tool Use & Developer Experience
- OpenClaw released a new TypeScript security hardening library that speeds up file operations by 10x @steipete.
- CodexBar 0.26.0 is live with support for Kiro and improved cost scoping @steipete.
- A new tool for indexing codebases with dependency graphs is specifically designed for AI agent context @tom_doerr.
Memory & Research
- Developers are building autonomous research loops to turn papers into reusable agent skills @koylanai.
- Persistent memory for recurring agent workflows is now available via new skill packages @tom_doerr.
Reddit Intel
From 'goldfish memory' to $500 monthly SDK bills, the honeymoon phase of agent development is meeting the reality of production.
The honeymoon of the agentic web is ending, and the 'hard yards' of production engineering have begun. This week, the narrative has shifted from what agents could do in a clean demo to why they are failing in the wild. We’re seeing a massive divergence between 'vibe coding' and deterministic coordination. Practitioners are grappling with the 'goldfish problem'—agents that forget context mid-stream—leading to a 40% predicted failure rate for enterprise projects that lack robust state management.
But as the gaps widen, the tooling is hardening. We’re seeing the rise of 'Agent OS' architectures like LibreFang that ditch Python's fragility for Rust-native performance, while the Model Context Protocol (MCP) is hitting the 'enterprise wall,' forcing a rapid pivot toward formalized security governance. Meanwhile, the 'credit trap' is becoming a real threat to margins; when parallel sub-agents can accidentally rack up $500 in monthly bills, cost-optimization isn't just a feature—it's a survival requirement. Today’s issue explores the technical hardening required to turn 'clueless geniuses' into reliable production teammates.
Beyond the Goldfish: Solving the Agentic State Management Crisis r/AI_Agents
The gap between impressive agent demos and production reliability is widening as practitioners grapple with 'accumulated state' issues. While agents look flawless in clean environments, real-world deployments suffer from the 'goldfish problem'—intelligent agents that wake up with zero memory of previous turns. This leads to wasted cost and time as agents start from scratch, a bottleneck that Indium.tech reports is driving a surge in Tool State Persistence strategies.
According to u/Beneficial-Cut6585, production environments require agents to navigate browser tabs in 'weird states' and handle mid-workflow parameter changes, which often leads to stale sessions and half-completed tasks. To combat this, developers are moving toward saving intermediate data—such as cursor positions in paginated APIs—allowing agents to resume work or recover from failures across multi-day sessions. This transition is critical, as analysts predict 40% of agentic AI projects may fail due to inadequate risk controls.
Memory management remains the primary bottleneck; systems often fail to distinguish between literal preferences and sarcasm, leading to 'truth at scale' failures. u/Distinct-Shoulder592 highlights that without a proper audit trail, these 'clueless geniuses' cannot be corrected. This is driving the adoption of context layers like r/HydraPlus to provide verifiable, long-term memory for autonomous systems.
MCP Ecosystem Scales: From Godot Daemons to On-Chain Micropayments r/mcp
The Model Context Protocol (MCP) is rapidly maturing into a globally distributed tool registry, with u/Lordddddddy demonstrating high-performance integrations like the Godot MCP daemon for instant game engine interaction. Monetization is simultaneously scaling via x402 micropayments on the Base mainnet, where tools are being wrapped for as little as $0.01 per call, though researchers warn that frameworks like NIST do not yet adequately cover MCP-specific threats like 'tool poisoning.' To bridge this gap, the FINOS AI Governance Framework has introduced specialized 'MCP Server Security Governance' to enforce supply chain verification and data integrity.
The Credit Trap: Rising Agent SDK Costs r/aiagents
Building on cloud-dependent agent SDKs is facing scrutiny as providers shift toward opaque credit-based models, with Anthropic’s new $100/month programmatic credit system being called a 'wake-up call' by u/robotrossart. Technical audits reveal unoptimized usage can reach $300–$500 per month per developer, while u/Clean-Revenue-8690 calculated that ChatGPT Business 'Codex-only' credits are reportedly 36.9% more expensive than standard API pricing. Practitioners are now implementing 'local safety valves' and prompt caching to slash production bills by up to 60%.
LibreFang and the Quest for Agent OS r/AI_Agents
Frustration with 'fragile' Python frameworks is driving a pivot toward Rust-native alternatives like LibreFang (OpenFANG), a system spanning 137,000 lines of code that treats agents as first-class operating system processes. u/techbrainceo notes the system achieves a 180ms cold start by using dual-metered WASM sandboxing for linear memory isolation. This architectural hardening moves away from 'vibe coding' toward deterministic coordination, which u/pauliusztin argues is the only way to prevent the redundant loops that currently plague agent latency.
Native MTP and Hardware Hacks Slash Latency for Local Agents r/LocalLLaMA
Multi-token Prediction (MTP) is becoming the production standard for local inference, with vLLM documentation confirming that native multi-token capability can eliminate the need for separate draft models. This shift allows models like Qwen 3.6 35B to achieve 1.5x throughput gains in iterative coding workflows, as reported by u/Jorlen. Hardware enthusiasts like u/do_u_think_im_spooky are bypassing cloud costs with dual RTX 5060 Ti setups, while a new Flash Attention fix for RDNA3 has finally closed the performance gap for AMD-based local agents.
Opus 4.7 vs. GPT-5.5: The Battle for Operational Stability r/LLMDevs
GPT-5.5 Pro currently dominates tool-use leaderboards with a 90.1 score on BenchLM.ai, while Opus 4.7 trails at 64.3% on the Agentic BWE-benchPro rankings. Despite the score gap, u/AdGlittering2629 reports that Opus remains superior for deep codebase navigation. As the industry moves toward 'compositional' failure analysis, new benchmarks like OdysseyBench are being introduced to simulate the long-horizon workflows that standard function-calling tests miss.
Figure 03: The 'Helix' Era of Autonomous Physical Agents r/ArtificialInteligence
Figure AI has unveiled Figure 03, a third-generation humanoid powered by the Helix vision-language-action core, designed for adaptive tasks like loading dishwashers rather than rigid programming. According to u/webthing01, these robots are now capable of running full 8-hour shifts at human-equivalent performance levels, signaling a major commercial pivot toward solving labor shortages in industrial environments.
arXiv Implements 1-Year Ban for LLM Hallucinations r/MachineLearning
arXiv has instituted a 1-year ban for researchers submitting papers with 'incontrovertible evidence' of unchecked LLM-generated errors, a move led by moderator Thomas G. Dietterich to combat academic 'slop.' While u/Nunki08 notes the necessity of the crackdown, enforcement remains controversial as 2025 research indicates detection tools frequently produce false positives, leading the industry to pivot toward specialized 'scientific integrity AI' for structural validation.
Discord Deep-Dive
OpenAI's Operator faces stiff competition as the industry pivots toward trajectory-based evaluation and MCP standardization.
Today’s landscape for agentic developers is shifting from 'can it do it?' to 'can it do it reliably at scale?' The launch of OpenAI’s Operator has set a high bar for browser-based action, yet it isn’t an uncontested crown. With Amazon AGI and specialized frameworks like Browser Use pushing the accuracy ceiling toward the mid-90s, the battle for the autonomous browser is intensifying.
But a model is only as good as its integration. The Model Context Protocol (MCP) has effectively become the 'USB-C for AI,' reaching critical mass with 78% enterprise adoption. This standardization, paired with hardened persistence layers in frameworks like LangGraph and graph-based memory systems like Mem0, suggests we are entering an era where agents aren't just toys, but durable components of the enterprise stack. As we move from static benchmarks to trajectory-based evaluations, the focus is squarely on the 'how'—ensuring that every tool call and reasoning step is as defensible as the final answer.
OpenAI Operator vs. Open-Source: The Battle for 95% Reliability
The launch of OpenAI Operator marks a significant shift from conversational AI to action-oriented agents, achieving an 87% success rate on the WebVoyager benchmark @timabdulla. While OpenAI highlights the model's fine-tuning for long-horizon planning OpenAI, the system is currently matching existing state-of-the-art specialized agents rather than redefining the ceiling. Industry benchmarks reveal a narrowing gap; Browser Use Cloud (bu-ultra) scores 78.0% on complex automation tasks, outperforming standard open-source models by 16 points Browser Use.
Meanwhile, the performance frontier is being pushed by Amazon AGI’s browser SDK, which recorded a 93.9% accuracy rate on the ScreenSpot Web Text benchmark, surpassing the results of both Anthropic’s Computer Use and OpenAI’s CUA Turion AI. The debate has shifted from simple execution to architectural efficiency: while Operator relies on a specialized vision-language model, frameworks like Browser Use leverage a hybrid approach of accessibility tree parsing and DOM manipulation to solve latency bottlenecks Helicone.
MCP Ecosystem Hits Critical Mass with 78% Enterprise Adoption
Anthropic's Model Context Protocol (MCP) has transitioned from a niche open-source project to the definitive 'USB-C for AI,' with 78% of enterprise AI teams reporting at least one MCP-backed agent in production. This scale is reflected in over 97 million SDK downloads and a public registry, PulseMCP, which has surpassed 5,500 servers providing instant connectivity to data silos Deepak Gupta MCP Manager. While the protocol reduces integration overhead by an estimated 40%, the Cloud Security Alliance is now tracking the 'MCP Top 10 Security Risks' to mitigate vulnerabilities like prompt injection Synvestable.
Beyond the Final Answer: Trajectory-Based Evaluation Redefines Agent Reliability
Static LLM benchmarks are increasingly viewed as insufficient for autonomous systems, driving an industry-wide shift toward trajectory-based evaluation that scrutinizes the entire sequence of tool calls. Unlike traditional grading, this methodology identifies where agents deviate into 'hallucination loops' or inefficient tool usage Galileo AI. Frameworks like AgentOps and LangSmith are being augmented by specialized tools like AgentEvals to achieve a 0.80+ Spearman correlation with human judgment, which is essential for catching silent failures that outcome-only metrics miss AgentEvals.
LangGraph Persistence Layers and ScyllaDB Integration Harden HITL Workflows
LangGraph has formalized the 'wait-for-human' pattern through its native checkpointer system, allowing agents to pause indefinitely for manual approval on high-stakes tasks. This architecture provides a 100% audit trail by saving the full state of the graph, enabling 'time-travel' debugging and 30% faster recovery in production environments using PostgresSaver @langchain. For enterprise scaling, ScyllaDB has emerged as a critical partner, providing the low-latency, durable state management required for billion-scale agentic data operations ScyllaDB.
Qwen2.5-Coder-7B Outpaces Llama 3.1 8B in Tool-Use Benchmarks
Qwen2.5-Coder-7B has demonstrated superior precision in handling nested JSON schemas and complex tool arguments compared to Llama 3.1 8B, achieving a 90.2% on HumanEval @QwenLM.
Persistent Memory Architectures: Mem0 and the Shift to Graph-Based AI Recall
Specialized memory frameworks like Mem0 are enabling agents to achieve a 22% reduction in token usage for recurring tasks by managing information as a structured graph of entities rather than static RAG Mem0 Docs.
HuggingFace Highlights
Hugging Face's 1,000-line framework targets the 'abstraction tax' as builders pivot to code-native agents.
The agentic landscape is undergoing a necessary pruning. For the past year, we have seen orchestration layers grow increasingly complex, often burying agent logic under mountains of JSON schemas and brittle tool-calling configurations. This week, the momentum shifted back to the code. The launch of 'smolagents' signals a move toward 'code-as-action,' where agents interact with the world through direct Python execution rather than structured text. This isn't just about simplicity; it's about performance. By bypassing traditional multi-agent abstractions, these minimalist systems are hitting 67% success rates on the GAIA benchmark while using significantly fewer logic steps.
However, this leaner approach arrives just as we receive a sobering reality check on agent reliability. Research from IBM and UC Berkeley highlights a persistent 'verification gap,' where agents often hallucinate success while failing the actual task. As we move from pilot enthusiasm to industrial reality, the focus is shifting toward specialized benchmarks and 'Physical AI' models that can ground high-level reasoning in verifiable execution. For developers, the message is clear: the path to production isn't through more abstraction, but through better verification and tighter, more efficient reasoning loops. In today's issue, we look at the frameworks, models, and evaluation tools leading this code-first charge.
The 'Smol' Revolution: Code-First Minimalist Agents
Hugging Face has fundamentally shifted the agentic landscape with the launch of smolagents, a minimalist library of approximately 1,000 lines that prioritizes 'code-as-action' huggingface/smolagents. By letting agents write and execute Python directly rather than wrestling with JSON tool-calling, the framework achieves a 67% success rate on the GAIA benchmark Hugging Face and a 30% reduction in logic steps compared to traditional multi-agent systems gitpicks.dev. This architectural leanness allows for Tiny Agents to be implemented in as few as 50 lines of code, leveraging the Model Context Protocol (MCP) to maintain provider-agnostic tool execution.
This movement to open-source 'Deep Research' is dismantling proprietary silos by moving from black-box API calls to inspectable, code-native architectures. Hugging Face has demonstrated that an agentic workflow using a CodeAgent can reduce the 'verification gap' through transparent, step-by-step logic that developers can debug in real-time. Community-driven implementations like MiroMind Open Source Deep Research and AutoSearch are expanding this capability to support 40+ search channels and MCP-native infrastructure, ensuring that long-form synthesis remains grounded in verifiable sources rather than model hallucinations.
While established frameworks like LangChain maintain an edge in community-driven scalability xpay.sh, smolagents is emerging as the high-velocity standard for developers seeking to bypass the 'abstraction tax' of complex orchestration layers. Specialized implementations like DeepMath further demonstrate the framework's capacity for handling complex reasoning through verifiable logic loops, suggesting a shift toward modularity where users 'bring their own models' to stateful Python environments like Jupyter Agent 2.
High-Velocity Operators: Democratizing GUI Automation and Computer Use
The 'Computer Use' frontier is expanding beyond proprietary labs with the release of the Holotron-12B family. These specialized operators demonstrate a 62.3% success rate on ScreenSuite, nearly doubling the baseline set by Claude 3.5 Sonnet. Optimized for real-time production, Holotron-12B offers a staggering throughput of 8.9k tokens/s on a single H100, prioritizing execution speed over general reasoning for 'pixel-to-action' workflows BenchLM.
Closing the Verification Gap: New Benchmarks Target Industrial Reality
New diagnostic frameworks are exposing a critical verification gap where agents frequently hallucinate success despite failing the actual task. Research using IT-Bench and MAST reveals that open-source models like GPT-OSS-120B suffer from compounding patterns averaging 5.3 failure modes per trace IBM Research and UC Berkeley. This lack of reliability is driving a shift toward specialized industrial benchmarks where failure rates often exceed 30%, forcing builders to address 3-7 step reasoning chains during live tool execution IBM Research.
Unified Tool Use and the Rise of Open Agent Ecosystems
Hugging Face is standardizing the 'Agentic Web' through the Unified Tool Use API, abstracting model-specific schema formats across Mistral, Cohere, and Llama.
Efficiency Breakthroughs in Long-Context and Physical Reasoning
DeepSeek-V4 introduces a 1 million token context window while reducing the KV cache by 90%, though researchers warn of potential 'needle-in-a-haystack' retrieval risks.
From Self-Play to Industrial E-Commerce: Multi-Agent RL
The AI vs. AI system uses deep reinforcement learning and Self-Play to train agents for adversarial competition and industrial coordination.
Vertical Agents: Precision Tooling for Medical and Data Domains
Google's EHR-navigator and the MedAgentBench framework are tackling the 'trust gap' in high-stakes healthcare environments.