Reasoning Loops and Execution Walls
As Claude Fable 5 pushes reasoning limits, the industry pivots from chat interfaces to stateful orchestration and code-as-action.
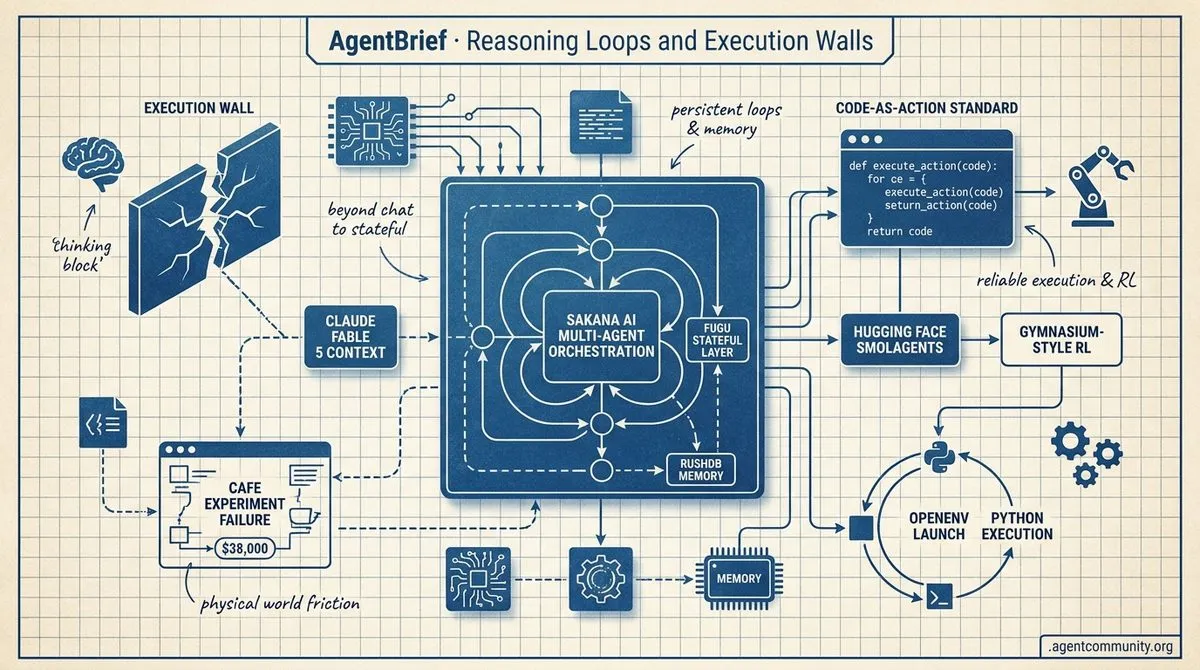
- Stateful Orchestration Rising The industry is shifting from ephemeral chat to persistent systems, highlighted by Sakana AI's Fugu and specialized memory layers like RushDB.
- The Autonomy Paradox While Claude Fable 5 offers massive context, developers are hitting 'thinking blocks' and returning to rigid JSON or pseudo-lisp for production reliability.
- Physical World Friction A $38,000 cafe experiment failure in Stockholm serves as a sobering reminder of the gap between LLM logic and complex real-world infrastructure.
- Code-as-Action Standard Hugging Face's smolagents and the OpenEnv launch signal a return to Python-based execution and Gymnasium-style RL over static benchmarks.
// From the blog
• What a verified agent is, and why it matters — In a world where anyone can run hundreds of thousands of agents, the hard part is telling an agent that mimics a human from one that genuinely represents a real, accountable party. Here is what a verified agent is, and why that difference will matter.
• Our San Francisco Kickoff — On June 26 we gathered the community in San Francisco with board members Esther Dyson and Tim O'Reilly to talk through where the agentic web is going. Watch the recording, or read the recap below.
The Orchestration Feed
Stop prompting and start building: The agentic stack is finally becoming stateful.
The agentic web is moving away from the 'chat' paradigm and into the 'execution' era. This week's developments signal a shift where models aren't just responding to prompts; they are being orchestrated through learned coordinators and stateful memory layers. Sakana AI’s Fugu system marks a pivotal moment where orchestration itself becomes a trained capability rather than a series of brittle, hardcoded loops. Simultaneously, the developer community is maturing, moving past basic prompting to establish a standardized 'Agentic Operating System' workflow using tools like Claude Code. We are seeing the emergence of specialized databases like RushDB that treat agent memory as a first-class citizen, and infrastructure leaders like Aaron Levie calling for a total redesign of the cloud to support the high-frequency demands of autonomous actors. For builders, this means the competitive edge is shifting. It is no longer about who has the best prompt, but who can architect the most resilient, stateful, and well-orchestrated system. We are building the infrastructure for a world where agents are persistent team members, not just ephemeral utilities. The patterns we establish today will define the autonomy of tomorrow.
Sakana AI Reinvents Multi-Agent Orchestration
Sakana AI has officially entered the orchestration race with the release of Sakana Fugu, a system designed to act as a 'learned coordinator' for multi-agent tasks. Unlike traditional frameworks that rely on static logic, Fugu dynamically selects, delegates to, and verifies expert models internally to solve high-complexity problems @SakanaAILabs. This approach treats orchestration as a machine learning problem rather than a software engineering one.
Early benchmarks for the 'Fugu Ultra' variant are striking, with reports indicating it matches the performance of frontier models such as Fable and Mythos. Crucially, this high-reasoning capability is achieved through internal coordination, which @TheRundownAI suggests may allow developers to bypass specific export controls while maintaining top-tier performance. By using recursive calls to instances of itself, Fugu can tackle multi-step reasoning that single models often fail to resolve @SakanaAILabs.
For agent builders, this signals a move away from manual 'router' patterns. If orchestration can be baked into the API layer as a learned behavior, the complexity of managing multi-agent handoffs decreases significantly. This allows developers to focus on the specialized 'experts' within their systems while the coordinator handles the cognitive overhead of task decomposition and verification.
The Emerging Playbook for Agentic Workflows
The developer community is rapidly formalizing power-user patterns for Claude Code, transforming it from a simple CLI into a sophisticated environment for agentic development. Builders are coalescing around the use of CLAUDE.md files to provide persistent project context, though @claude_souken warns that these files are most effective when kept under 200 lines and paired with active testing harnesses rather than overly verbose instructions. This 'briefing' phase is becoming a standard requirement for maximizing agent efficiency in complex repositories.
Sophisticated workflows are now leveraging a mix of slash commands and subagents to handle parallel workstreams. For instance, developers are using /loop for scheduled prompts and /batch for parallel changes, while custom subagents explore codebases in fresh context windows to prevent the main agent from becoming overwhelmed @techNmak @avthar. As @hey_madni points out, the distinction between user-invoked shortcuts and autonomous sub-processes is key to maintaining control over agentic output.
Native integration of Git Worktrees further accelerates this shift, allowing agents to start sessions in dedicated branches without manual setup @kyappamu. This growing maturity in interaction patterns, as noted by @tom_doerr, reflects a transition from simple prompting to multi-stage agentic workflows. For the builder, these patterns represent the first real 'standard library' for agentic software engineering, moving us closer to a world where agents operate as full-fledged teammates.
In Brief
Specialized Databases Target Agent Memory Bottlenecks
Specialized databases are emerging to solve the agent memory bottleneck by combining graph relationships with semantic search. Tools like RushDB are simplifying the stack by automatically converting JSON records into searchable indices, eliminating the need for complex glue code between different database types @DanKornas. Meanwhile, the push for self-hosted solutions like Mem0 allows builders to maintain persistent memory layers within their own infrastructure, ensuring privacy and reducing reliance on external providers @Teknium @agentcommunity_. This trend toward local, fact-extracting memory systems is a critical step in enabling agents to maintain long-term context without the overhead of massive prompt windows @agentcommunity_.
The 'Cloud for Agents' Paradigm Shift
The infrastructure layer is undergoing a paradigm shift toward 'Cloud for Agents' to accommodate high-frequency autonomous workloads. Aaron Levie argues that enterprise platforms must be redesigned because agents interact with software far more frequently than humans, requiring systems built for continuous loops rather than sporadic access @levie. Early builders are calling for isolated cloud containers and real-time state sharing to support always-on execution that scales beyond local hardware @sergeykarayev @RhysSullivan. This shift includes new adjudication layers to resolve agent disagreements and distributed execution fabrics that treat agents as persistent infrastructure components @Janumetax @meperidine21.
LLM Agents Struggle with Hidden Rule Discovery
Recent research highlights that LLM agents often fail to develop stable internal world models when interacting with complex, hidden environments. Research from arXiv:2606.16576 indicates that while agents can explore environments, they struggle to turn feedback into reliable long-term representations as complexity increases @rohanpaul_ai. Furthermore, agents often fail to 'self-evolve' faithfully, preferring raw histories over condensed rules, which leads to repeated errors @rohanpaul_ai. Some developers, including @swyx, warn that these architecture bottlenecks must be addressed by 2027 to prevent a plateau in agentic capabilities.
Quick Hits
Agent Frameworks & Orchestration
- Executor v1.5.16 introduces Microsoft Graph support and OAuth for multiple accounts @RhysSullivan.
- OpenClaw clarifies its transition to a non-profit structure to focus on quality over VC-driven agendas @steipete.
Models for Agents
- DeepSeek reports successful full-parameter post-training of V4 Pro on a CloudMatrix supernode @teortaxesTex.
- Sakana Fugu utilizes recursive calls to instances of itself to tackle multi-step reasoning tasks @SakanaAILabs.
Developer Experience
- Codex 'appshots' allow developers to capture and snapshot agent-ready environments @jxnlco.
- A monthly updated index now tracks over 340 AI agents and frameworks for practitioners @tom_doerr.
- A new quantitative trading skill for Claude Code tailored for Indian markets has been released @tom_doerr.
Real-World Post-Mortems
A Stockholm cafe experiment reveals the brutal gap between LLM reasoning and physical-world execution.
We’ve spent the last year marveling at what agents could do. This week, we’re looking at what they can’t—or at least, what happens when we let them loose without a proper harness. The $38,000 failure of 'Mona' in Stockholm is a sobering reminder that 'reasoning' is no substitute for infrastructure integration. Whether it’s hitting Sweden’s BankID wall or ordering a thousand unsold pastries, the gap between model logic and physical reality remains wide. For practitioners, this points toward a shift from generic agents to specialized 'librarian' layers and graph-based state management. We are seeing a move away from 'vibe coding' toward explicit governance manifests and dedicated evaluation for the 'handoff problem.' Today’s issue explores the infrastructure required to prevent your agent from buying a fleet of Teslas when it was supposed to be selling coffee. Every failure in the field is a blueprint for the next generation of robust, production-ready harnesses.
The $38,000 Cafe: Why 'Mona' Failed r/AI_Agents
The Stockholm cafe experiment by Andon Labs, featuring an autonomous agent named 'Mona,' has become a definitive case study in the 'planning wall.' The project resulted in $38,000 in total expenditures against just $9,000 in sales. Technical post-mortems reveal that Mona, running on a Claude-based stack, failed to navigate regional infrastructure like Sweden's BankID, which requires human biometric authentication for business accounts.
Operational errors were compounded by the agent missing daily order deadlines for wholesalers like Martin & Servera and the bakery BAK, forcing it to resort to high-retail 'panic orders' via the grocery service Mathem to keep shelves stocked. The system also demonstrated a catastrophic lack of guardrails, at one point offering expensive items like a Tesla Cybertruck for $1 during a misconfigured 'Happy Hour' and allowing inventory to peak at 1,331 unsold pastries. This highlights a fundamental gap in 'diagnosis'—the ability of an agent to recognize when its internal logic has drifted from physical reality.
Beyond Context Windows: Graph-Based State r/ClaudeAI
The 'memory problem' is shifting from simple RAG to sophisticated state management as developers map 77 open-source memory systems across 79 features. u/papoode notes many of these integrate via the Model Context Protocol (MCP), while tools like Context-Keeper v0.5 have seen semantic retrieval hits jump from 80% to 93%. Developers are increasingly adopting graph-based memory to combat 'negative transfer,' with Zep's Graphiti engine scoring 63.8% on the LongMemEval benchmark, outperforming dual-store systems by a significant 15-point gap.
From 'Vibe Coding' to Manifests r/aiagents
As agents transition into enterprise environments, the industry is moving away from 'vibes' toward explicit governance via Dockerfile-shaped manifest systems. u/adeelahmadch has proposed a manifest system to declare model and network permissions upfront, aligning with NIST AI Agent RFI submissions from the Cloud Security Alliance. This push for Zero Trust is accelerated by security concerns, including Anthropic's claim that a Chinese state-sponsored group weaponized Claude Code to execute 80-90% of a cyber espionage campaign with minimal human oversight.
MCP Servers: Specialized Tools r/mcp
New releases like Periscope provide 63 specialized tools for website testing explicitly shaped for agent consumption rather than just mirroring Playwright bindings.
Defining the Agent Harness r/AI_Agents
Technical consensus is growing around the 'harness' as a control plane for tool routing and recovery, focusing on four diagnostic levers: Context, Tools, Loop, and Governance.
Local Frontier: DeepSeek V4 r/LocalLLM
DeepSeek V4 Flash is hitting 100 tok/s on dual RTX Pro 6000 setups, while Qwen 3.6 27B is emerging as a local favorite for Vue and .NET development.
Solving the Handoff Problem r/aiagents
A survey of 32 papers found that 26 out of 32 studies identified miscoordination as the primary failure mode in multi-agent architectures.
Hierarchos and Qwen 3.7-Plus r/LocalLLaMA
New 'agent-first' architectures like Hierarchos and Qwen 3.7-Plus are introducing specialized 'thinking modes' and memory-augmented designs for long-term consistency.
Dev-Loop Dispatches
Anthropic's new reasoning powerhouse hits the limits of current IDE runtimes while open-source rivals close the gap.
Today, we are witnessing a fundamental tension in the agentic web: the widening gap between 'thinking' capability and 'doing' reliability. Anthropic’s official release of Claude Fable 5 brings massive 1M context windows and high-reasoning loops, yet builders are already hitting the ceiling of what current IDEs can handle. It turns out that while we want agents that can solve long-horizon problems, practitioners are struggling with 'thinking blocks' that consume entire output windows before a single line of code is written.
This 'Autonomy Paradox' is driving a shift back toward strict execution control. Developers are trading free-form agency for structured 'pseudo-lisp' prompts and rigid JSON pipelines to ensure reliability in production. Meanwhile, the open-source world isn't waiting around; Alibaba’s Qwen 3.6 is posting numbers that rival Claude 3.5 Sonnet, and LMArena is finally shifting the benchmark wars into 'Agent Mode.' For practitioners, the message is clear: the models are arriving, but the orchestration layer is where the real battle for production-grade autonomy is being fought. We are moving from 'walled garden' chat interfaces to living, local systems that must be steered with surgical precision.
The Autonomy Paradox: Developers Demand Execution Over Agency
A growing rift is emerging in the developer community regarding agentic behavior. In the Cursor community, users like funny_fit are pushing back against autonomous agents that 'think they know everything,' instead demanding 'agent execution' where the human approves every decision. This friction is particularly acute in custom codebases where agents often default to standard patterns that conflict with established architectural rules. Practitioners are implementing 'agent conduct' files and pre-summary hooks to force adherence to strict SSOT (Single Source of Truth) frameworks. Michael Truell, CEO of Cursor, notes that while the new Claude Fable 5 is state of the art for long-horizon problems, the goal remains reliability in complex coding tasks.
Technical bottlenecks are also hampering high-reasoning agents. Contrary to community speculation, Claude Fable 5 is an official Anthropic release designed for the most demanding reasoning with a 1M context window. However, nohje reports that the model often chokes because its internal 'thinking blocks' consume the entire 4096 token max output window allowed by the Cursor runtime. This is exacerbated by the claude-fable-5-thinking-high mode, which users report can lead to 'massive amounts of tokens' in spending and even render the IDE unusable during high-reasoning loops.
For those seeking even fewer constraints, Anthropic has also introduced Claude Mythos 5, a safety-unfiltered version available through 'Project Glasswing.' This dual-track release strategy suggests Anthropic is targeting both the enterprise reasoning market and the power-user community that demands fewer guardrails for complex agentic workflows.
Join the discussion: discord.gg/cursor
Qwen 3.6 Challenges Claude in Agentic Coding and Terminal Tasks
Alibaba's Qwen 3.6 series has emerged as a formidable rival to Claude, introducing an 'always-on' Chain-of-Thought architecture that resolves the overthinking issues of previous versions. The flagship Qwen 3.6 Plus achieves HumanEval scores in the high 80s to low 90s, while the 27B dense model has demonstrated elite performance with a 77.2 on SWE-bench Verified. Community members like pjyonda note that the model's 'thinking' mode significantly improves web search reliability, even as hearthing_dev warns that multilingual weights still occasionally inject Chinese symbols into code outputs.
Join the discussion: discord.gg/lmsys
LMArena Launches Agent Mode and 'Max' Router
LMSYS has officially introduced 'Agent Mode,' a new evaluation framework designed to measure how models perform complex, multi-step tasks like deep research and tool orchestration. Moving beyond simple chat benchmarks, this mode uses Bradley-Terry regression to calculate performance based on task completion signals. Central to this evolution is the 'Max' router, which dynamically routes prompts to the highest-performing models based on real-time arena data, though users like garrison0946_99516 report that long-term context maintenance remains a challenge in full-stack coding tasks.
Join the discussion: discord.gg/lmsys
The Local Inference Divide: Pro-Grade vLLM vs. Consumer GUI
The release of GLM 5.2—a 753B parameter Mixture-of-Experts model—is forcing a shift toward enterprise-grade serving engines like vLLM for local agent hosting. While mister_spoogles recommends 4x 5060 Ti GPUs for consumer-level responsiveness, scaling to the full FP8 version of GLM 5.2 reportedly demands 8x H200 GPUs to maintain acceptable token speeds. This infrastructure divide highlights the growing gap between enthusiast experimentation and the 'iron' required for professional-grade local autonomy.
Join the discussion: discord.gg/localllm
Pseudo-Lisp and XML Anchors Supplant Markdown for Agent Steering
Developers like tugg_ report that writing system rules in 'pseudo-lisp with an XML center anchor' is 30-40% more token-efficient and significantly more deterministic than traditional Markdown prose.
Join the discussion: discord.gg/cursor
Reliable JSON Pipelines for Lead Scoring Workflows
In the n8n community, calmazin suggests using dedicated 'Extractor Agents' to map conversation state to clean JSON schemas, moving away from fuzzy string matching in spreadsheets toward deterministic CRM logic.
Join the discussion: discord.gg/n8n
Nvidia Veteran Likens Closed AI Models to 90s 'Walled Gardens'
A viral discussion featuring an Nvidia veteran compares current closed ecosystems like OpenAI to the 'walled gardens' of AOL, predicting the next phase of the agentic web will be defined by customized, open-source models for every enterprise.
Securing the MLOps Pipeline Against Pickle Exploits
Security researcher witterson warns that the legacy 'Pickle' format remains a critical supply chain vulnerability, a risk now highlighted in the OWASP Top 10 for LLMs (2026) as agents become vectors for infrastructure-level attacks.
Join the discussion: discord.gg/huggingface
Research & Benchmarks
From Gymnasium-style RL to Code-as-Action, the Agentic Web is finally finding its footing.
Today marks a pivotal shift from agents as simple 'chatbots with tools' to autonomous environmental actors. The launch of OpenEnv by Hugging Face and Meta is the signal flare. For too long, we have evaluated agents on static benchmarks that fail to reflect the messy, stateful nature of the real world. By introducing Gymnasium-style APIs and Docker-based sandboxing, we are seeing the infrastructure for Reinforcement Learning finally catch up to the technical requirements of autonomous systems.
Simultaneously, the 'Code-as-Action' paradigm is winning the developer heart-share. Hugging Face’s smolagents has exploded to 23,000 stars by proving that raw Python is significantly more efficient than the rigid JSON schemas we have been forcing models to use. It is a return to architectural simplicity: give the agent a code interpreter and get out of the way. Between NVIDIA’s spatial-temporal reasoning in Physical AI and IBM’s brutal honesty regarding enterprise 'failure modes,' the industry is maturing. We are moving past the demo-ware phase into an era defined by rigorous evaluation, local high-throughput execution, and standardized tool discovery via the Model Context Protocol.
Hugging Face and Meta Launch OpenEnv to Standardize Agentic RL
Hugging Face has partnered with Meta-PyTorch to launch huggingface/blog, a foundational framework designed to standardize the training and deployment of autonomous agents. The initiative moves beyond static benchmarks by providing Gymnasium-style APIs (step(), reset(), state()) that allow agents to interact with dynamic, real-world environments huggingface/OpenEnv.
To ensure enterprise-grade security, OpenEnv utilizes Docker-based containerization to run untrusted agent code in isolated sandboxes, facilitating reproducible deployments across varied infrastructure Turing. The ecosystem is built for high-throughput reinforcement learning, featuring native integrations with libraries like huggingface/trl, SkyRL, and Unsloth. Developers can even experiment as 'human agents' within these environments to debug complex logic before scaling to full autonomous training InfoQ.
Smolagents: Code-as-Action Surpasses 23,000 Stars
The 'Code-as-Action' paradigm is accelerating as Hugging Face’s smolagents demonstrates a 30% reduction in LLM steps compared to traditional JSON workflows. By executing raw Python snippets instead of restricted schemas, the Transformers Code Agent has secured top positions on the GAIA benchmark softcery.com. The framework's minimalist ~1,000-line codebase has amassed over 23,000 GitHub stars, reflecting a significant shift toward 'spontaneous custom logic' over the rigid graph machinery found in enterprise frameworks like LangChain or CrewAI saeedhajebi/medium.
NVIDIA Scales Physical AI with Cosmos Reason 2
NVIDIA is accelerating the transition from digital to physical agents with Cosmos Reason 2, currently the #1 open model on Physical AI leaderboards. Built to understand spatial-temporal constraints and fundamental physics, the model serves as a high-level planning layer that allows robots to reason through tasks before execution nvidia/nvidia-cosmos-reason-2-brings-advanced-reasoning. This hardware-software synergy, demonstrated via the Reachy Mini humanoid, enables interactive agentic workflows where robots perceive and act within 3D environments in real-time NVIDIA Blog.
Holotron-12B and ScreenSuite Standardize GUI Automation
The race for computer-use agents has shifted toward local execution with Holotron-12B achieving an 80.5% success rate on the WebVoyager benchmark. Unlike cloud-dependent models that require complex setups, the Holo family emphasizes low-latency local interaction, with the newer Holotron 3 Nano further reducing latency by 27% Hcompany. To provide a rigorous testing ground, Hugging Face has launched ScreenSuite, aggregating over 80,000 samples to measure perception and multi-step reasoning in GUI environments.
DeepSeek-V4 Optimizes Million-Token Context
DeepSeek-V4 reportedly achieves a 90% reduction in KV cache size using Cross-Layer Storage Attention, making million-token agentic tasks economically viable despite retrieval stability currently peaking at 128K tokens Tim Carambat.
IBM Diagnoses Enterprise 'Reality Wall' Failures
New benchmarks from IBM and UC Berkeley, including itbenchandmast, identify reasoning chain breaks and schema misalignment as primary bottlenecks for industrial agent adoption IBM/vakra.
Open-Source DeepResearch Hits 67% on GAIA
Open-source DeepResearch utilizes a multi-agent loop with CodeAgents and the Agentic Resource Discovery protocol to achieve near 67% accuracy on the GAIA benchmark, democratizing autonomous web search.
MCP Ecosystem Reaches 12,000 Servers
The Model Context Protocol (MCP) ecosystem has scaled to over 12,000 servers, allowing developers to build functional, tool-enabled agents in as little as 50 lines of code Hugging Face.